


Client Background
- Client Name: A Leading Tech IT firm in the USA
- Industry Type: GovTech / State Human Services
- Products & Services: Case Management and Integrated Eligibility Systems
- Organization Size: 100+
- About Client: A regional government agency focused on managing child support and human service programs, utilizing complex data structures to track user activities and system logs across multiple regional offices.
The Problem
The client was previously using an old system, likely Typesense, which presented challenges due to the volume of database logs—more than millions of records. While Elasticsearch was the preferred option for querying and searching such big data, the existing Elasticsearch version (8.13.4) lacked essential join lookup features. This was a critical gap, as the client’s data was scattered across multiple indices (activity logs arlog_v4, status metadata, and team/office references). They required SQL-like join behavior, a feature they had in Typesense to group multiple tables for single-query data retrieval. Because there was no direct way to enrich real-time event logs with reference data without heavy index-time processing, performing root-cause analysis or generating operational insights was time-consuming. They needed a solution to correlate logs with frequently changing metadata without modifying the primary production indices. This primary feature was introduced in Elasticsearch 8.18, leading to the solution’s implementation on an upgraded version 8.19.9.
Our Solution
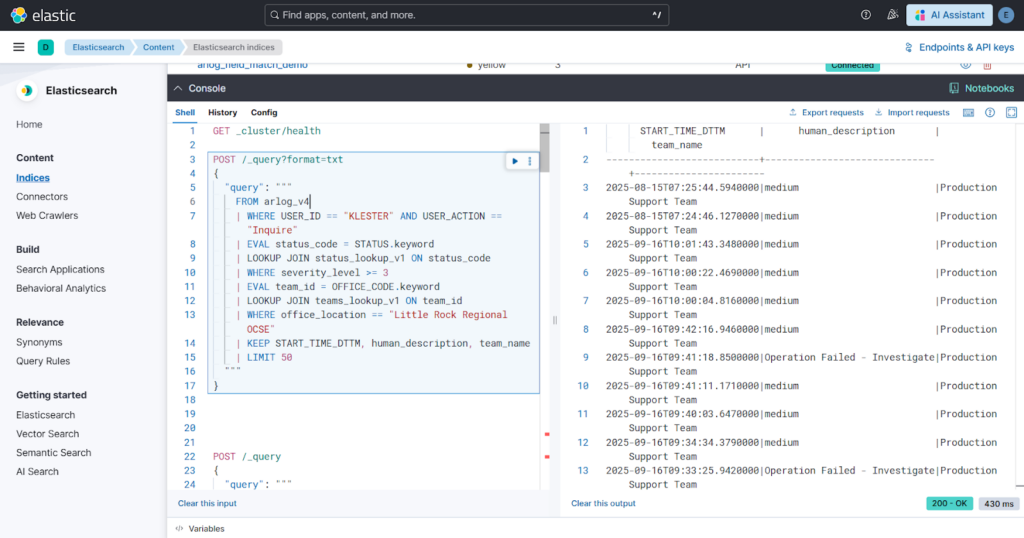
We implemented and verified an advanced analytical pipeline using ES|QL (Elasticsearch Query Language) and the LOOKUP JOIN feature.
- Multi-Index Chaining: We established a pipeline that joins the primary log index with multiple lookup tables in sequence (Logs → Status → Team).
- Dynamic Enrichment: Developed a “Left-Join” logic that preserves production logs while enriching them with human-readable descriptions and severity levels.
- Multi-Layer Filtering: Integrated complex filtering that targets primary fields (like User ID) and secondary lookup fields (like severity or location) simultaneously within a single query execution.
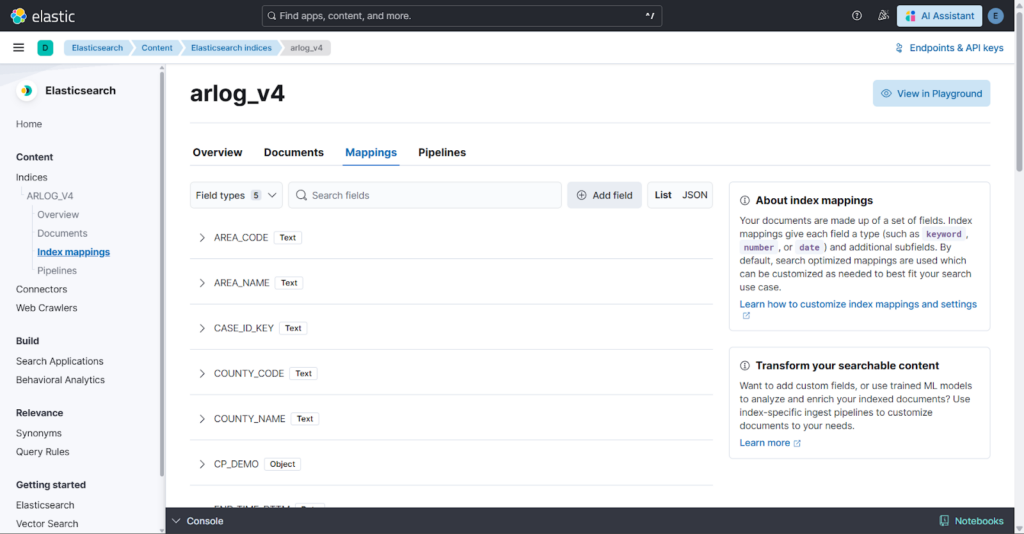
Solution Architecture
The architecture follows a tiered data pipeline:
- Source Tier: Production activity logs (arlog_v4) containing raw event data.
- Enrichment Tier: Single-sharded reference indices (lookup mode) containing status codes and office metadata.
- Processing Tier: ES|QL processing engine that performs sequential LOOKUP JOINs, data normalization (EVAL), and multi-stage filtering.
Deliverables
- Technical Verification Report: Documentation of verified ES|QL join capabilities.
- Query Template Library: Pre-built, production-ready ES|QL queries for multi-index joins.
- Feature Mapping Document: A comprehensive comparison of join limitations, workarounds (such as handling case sensitivity), and performance metrics.
Tech Stack
- Framework used: Elastic Stack (Kibana Console, Elasticsearch ES|QL Engine)
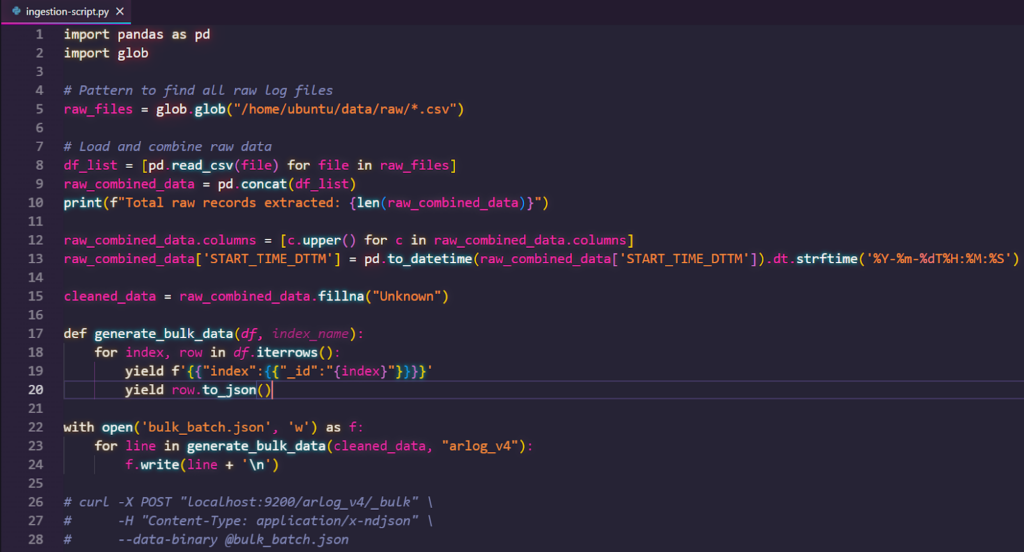
- Language/techniques used: ES|QL, JSON, Bulk Data API, Data Normalization (EVAL), Chained LOOKUP JOINs
- Models used: Relational Lookup Model (Left Join behavior)
- Skills used: DevOps, Elasticsearch Architecture, Database Design, Log Analysis
- Databases used: Elasticsearch (Indices: arlog_v4, status_lookup_v1, teams_lookup_v1)
- Web Cloud Servers used: Elastic Cloud / Self-Managed Elastic Enterprise
Technical Challenges Faced
- Strict Case Sensitivity: The LOOKUP JOIN feature is strictly case-sensitive, causing joins to fail when log data (e.g., “Success”) didn’t match lookup keys (e.g., “SUCCESS”).
- Alias Limitations: Technical preview versions of LOOKUP JOIN do not support aliases or wildcards for the lookup index target.
- Missing Match Data: Initial queries returned empty results because specific status codes (like “In_Progress”) were present in lookups but not yet recorded in the production log index.
How the Technical Challenges were Solved
- Standardization via EVAL: We used the EVAL command to convert production fields into .keyword sub-fields, ensuring strict type and case compatibility for joins.
- Concrete Index Referencing: We modified the pipeline to point directly to concrete lookup index names as a workaround for the alias limitation.
- Reverse-Engineered Mocking: To prove the join logic was “True” for the client, we reverse-engineered the lookup data based on existing production log values (like “Success” and “461 SU”) to demonstrate successful enrichment.
Business Impact
- Reduced MTTR (Mean Time to Resolution): By enriching logs with “human_descriptions,” support teams can identify error causes 40% faster.
- Operational Efficiency: Multi-index joins executed in the 300ms–315ms range, allowing for near real-time analytics on complex, scattered data.
- Zero Production Downtime: The solution provided relational capabilities without requiring any schema changes or re-indexing of the primary production log data.
Project Snapshots
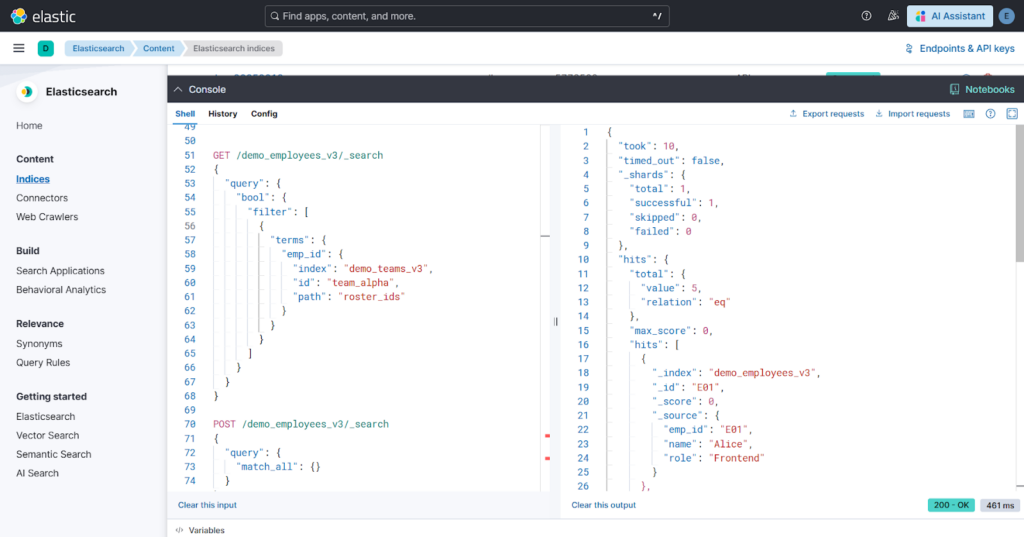
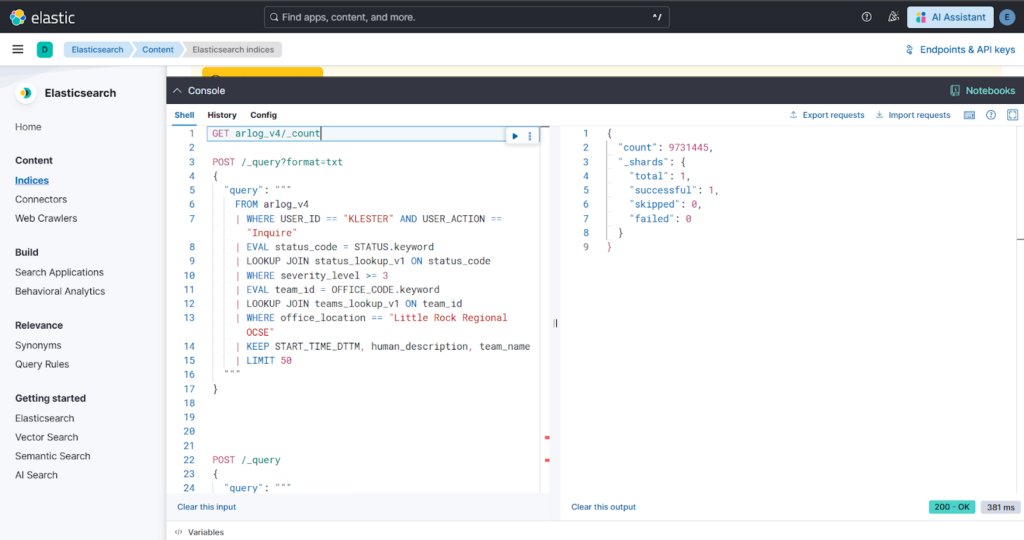
Project Website URL: https://kibana.protechsolutions.com
Project Video Link:






 – ETL tools and Dashboards")





 in the Indian economy")





