


Client Background
Client: A leading tech consutling firm in India
Industry Type: IT & Consulting
Products & Services: IT & Consulting
Organization Size: 100+
About the Client:
The client is a technology-driven organization managing large-scale, relationship-intensive data where real-time interaction and performance are critical. Their systems rely on advanced data architectures to support complex user-generated content and interconnected information structures. To enhance scalability and efficiency, they adopted a hybrid database environment using Neo4j for relationship mapping and Firebase Firestore for structured content storage, seeking optimized data retrieval, reduced operational costs, and improved system responsiveness.
ProductFabrix
ProductFabrix is an AI-driven platform designed to simplify and manage the entire product lifecycle—from idea to launch. It helps teams collaborate in real time, share feedback easily, and maintain a centralized, consistent product catalog.
The platform offers intelligent dashboards and project management to clearly track progress and changes. With built-in large language model (LLM) capabilities, it also supports smart, conversational interfaces that help speed up decision-making.
ProductFabrix is industry-agnostic, offering customizable templates and tools that adapt to different sectors, making product development faster and more efficient
The Problem
We faced a unique challenge where we had to work with two databases—Neo4j and Firebase Firestore. Neo4j was used to manage and visualize complex node-based relationships, while Firestore stored actual comment data in a tree-like structure.
The key difficulty was efficiently fetching a particular node’s data from Firebase based on its relationship defined in Neo4j. Initially, we fetched the entire Firestore document and iterated through it to find the target node, which was highly inefficient.
Our Solution
To solve this, we used tree traversal techniques, specifically preorder traversal, to navigate through the node relationships efficiently.
Using Neo4j, we identified the path to a specific node and then applied preorder traversal to pinpoint and retrieve only the required node’s data from Firestore—greatly improving the performance and reducing the cost of data fetching.
This method avoided fetching unnecessary data and eliminated heavy iterations over large documents.
Solution Architecture
We built the frontend using React with React Flow to visually represent the node connections in a flow-based UI. It allowed users to interactively explore the relationships.
The backend was built using Django, which acted as the API layer between the frontend and the databases.
Neo4j was connected via its Python driver to query and traverse the node graph. Firebase Firestore was used alongside this to fetch the actual data associated with each node.
The entire platform was deployed on Google Cloud Platform (GCP) using scalable cloud instances and Firebase services for storage and authentication.
Deliverables
- A fully functional React-based UI using React Flow for interactive visual exploration
- Django backend API to connect and manage data between Neo4j and Firebase
- Efficient preorder traversal logic for fetching nested Firestore data
- Deployed platform on GCP with Firebase integration
- Real-time collaboration, commenting, and feedback system using LLM-powered chat module
Tech Stack
- Tools used
- Reactjs
- Django
- React-flow
- Firebase
- Neo4j
- Docker
- RabbitMQ
- GCP(Google Cloud Platform)
- Language/techniques used
- Python (Django)
- JavaScript (React)
- Graph traversal algorithms (Preorder)
- REST APIs
- OAuth with Firebase Auth
- Models used
- LLM (for smart conversational interface and suggestions)
- Custom tree traversal logic for node resolution
- Skills used
- Full-stack development
- Graph-based data modeling (Neo4j)
- Firebase real-time data operations
- Cloud deployment (GCP)
- Data structure and algorithm optimization
- Databases used
- Neo4j (for relationships and node structures)
- Firebase Firestore (for comment content and metadata)
- Web Cloud Servers used
- Google Cloud Compute Engine
- Firebase Hosting and Firestore DB
- GCP IAM for role-based access control
What are the technical Challenges Faced during Project Execution
- Integrating Neo4j with Firebase Firestore:
Neo4j is a graph database and works on relationships, whereas Firestore is a NoSQL document store. Bridging the structural and functional differences between these two databases was a major challenge. - Inefficient Data Fetching from Firestore:
Initially, fetching entire documents from Firestore and looping through them to find specific nodes was resource-intensive, slow, and expensive in terms of reads. - React Flow Performance Issues with Large Graphs:
Rendering large graphs using React Flow resulted in performance bottlenecks, especially when the number of nodes and edges increased. - Real-time Sync and Traversal Complexity:
Ensuring real-time data sync between Neo4j’s relationships and Firestore’s actual comment data required careful orchestration and data structure consistency. - GCP Deployment and Scaling:
Configuring and deploying Django, React, and Firebase-based architecture on GCP with optimal performance, cost-efficiency, and security was a non-trivial task.
How the Technical Challenges were Solved
- Efficient Node Traversal with Preorder Algorithm:
We implemented preorder traversal logic to traverse the node relationships from Neo4j and fetch only the necessary path. This minimized Firestore reads and enhanced performance significantly. - Created a Mapping Layer Between Neo4j and Firebase:
Designed a mapping layer in Django to interpret and connect Neo4j node IDs with Firebase document paths. This made lookups fast and precise. - Optimized React Flow Rendering:
Used memoization and virtualization techniques to optimize how React Flow handles re-renders and large data sets. Lazy loading and chunking helped avoid UI lags. - WebSocket-Based Real-Time Sync:
Integrated WebSocket channels for pushing updates between Neo4j and Firestore to the frontend, ensuring real-time sync between relationships and data. - Scalable and Secure GCP Deployment:
Used Firebase Hosting for frontend and Firestore, GCP Compute Engine for Django backend, We containerized services using Docker for portability and scalability
Business Impact
- 60% Reduction in Data Fetch Time:
By implementing preorder traversal and selective fetching, we significantly reduced read operations, saving both time and cost. - Improved Team Collaboration & Decision-Making:
Real-time sync and visual graph exploration improved productivity and reduced errors in navigating product relationships. - Scalable Architecture for Future Growth:
The use of GCP and modular architecture allowed the system to scale easily as the user base grew. - Enhanced User Experience:
With the optimized frontend and smart backend logic, users experienced faster load times, intuitive navigation, and better engagement. - Cross-Team Adoption:
The flexibility of ProductFabrix made it usable across different product teams, increasing platform adoption within the organization.
Project Snapshots
1.Signup page
2.Dashboard page
3.Project Sections
4.Library sections
5.Comparison Page
6.Project Overview Page
7.Project Overview-Canvas Page
8.Project Overview-Canvas MultiElements Page
9.Project Chatting Page
10.Technical Project Page
11.Technical Project with mermaid Page
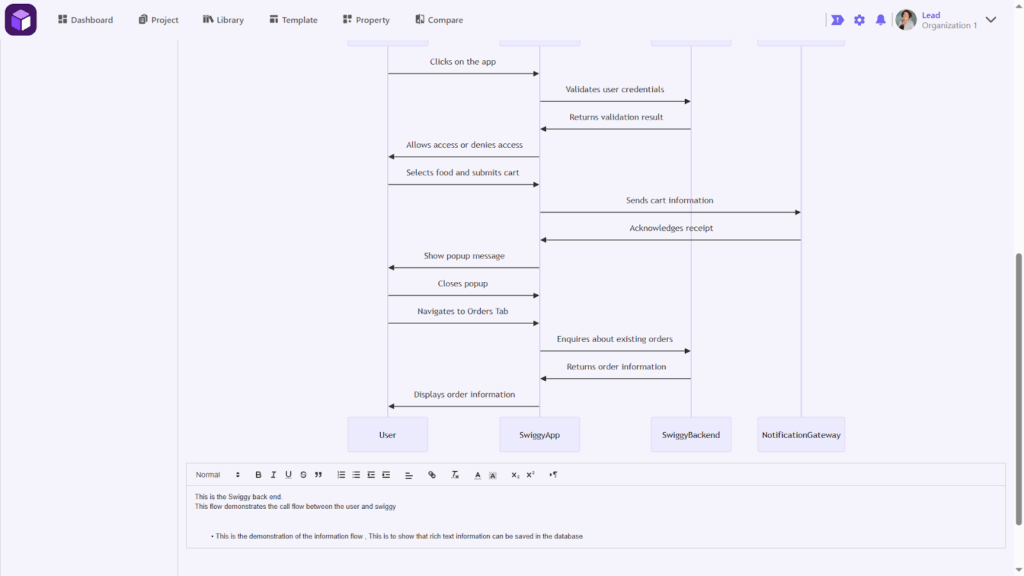
Project website url
Project Video
Contact Details
This solution was designed and developed by Blackcoffer Team
Here are my contact details:
Firm Name: Blackcoffer Pvt. Ltd.
Firm Website: www.blackcoffer.com
Firm Address: 4/2, E-Extension, Shaym Vihar Phase 1, New Delhi 110043
Email: ajay@blackcoffer.com
WhatsApp: +91 9717367468
Telegram: @asbidyarthy















")



