


Client Background
Client: A leading retail firm in the USA
Industry Type: Retail
Products & Services: Retail Business, e-commerce
Organization Size: 100+
The Problem
To develop an ETL discovery tool that can answer the queries related to ETL pipelines in conversational format. The areas of the concerned queries should include Environment Analysis, Workflow Analysis, Data Source and Target Mapping, Transformation Logic, Data Volume and Velocity, Error Handling and Logging and Security and Access Control.
Our Solution
In developing our solution, we began by aggregating Open-Source Generic ETL Tool Code from various repositories on GitHub and other relevant sources. Subsequently, we meticulously fine-tuned the collected ETL tool code, organizing and saving it into distinct folders, each containing different ETL pipelines.
Following this, we implemented an OpenAI Assistant, integrating it with all the refined ETL pipelines. To facilitate communication with these pipelines, we employed the OpenAI Assistant ID within our Flask API.
For the user interface, we opted for a Streamlit front-end, providing a seamless and user-friendly interaction with our OpenAI Assistant and the integrated ETL pipelines.
Solution Architecture
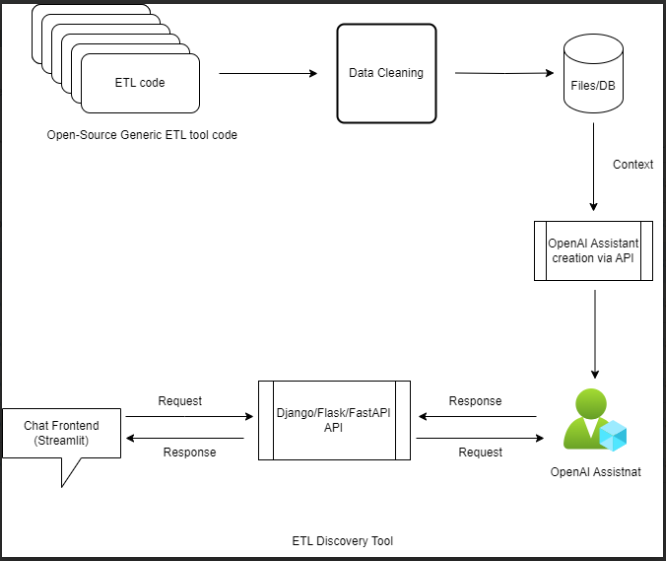
ETL Discovery Tool serves as the core engine for Extract, Transform, and Load (ETL) operations. It is designed to handle data extraction, transformation, and loading tasks efficiently. It will be used for training the OpenAI model on the ETL Discovery tools.
Step 1. Open-Source Generic ETL Tool Code:
The Open-Source Generic ETL Tool serves as the core engine for Extract, Transform, and Load (ETL) operations. It is designed to handle data extraction, transformation, and loading tasks efficiently. It will be used for training the OpenAI model on the ETL Discovery tools.
Step 2. Data Cleaning:
Data Cleaning is a critical stage that involves cleansing and pre-processing raw data to enhance its quality and integrity. In this step the ETL understands the expected data format that is organized and cleaned for uniformity of data.
Step 3. Files/DB
Represents the storage or databases utilized for storing processed data. In this step, solutions for processed data the code files will be arranged and catalogued so that they are ready to be used by the OpenAI Assistants API.
Step 4. OpenAI Assistant Creation via API:
This step involves creating an OpenAI Assistant using the OpenAI API.
- Configuring the OpenAI Assistant
- Configure .env file with OpenAI API Key
- We will upload the files to the Assistant for it to be added in context.
- Run assistant creator.py file for generating OpenAI Assistant ID
- After Generating OpenAI Assistant id look into terminal save the generated ID into .env file
- We will get the assistant ID that is to be used later.
Step 5. OpenAI Assistant:
In this step, the Assistant that is created from previous step will be queried by the API with instructions for the context accommodation.
- Features and Capabilities: functionalities supported by the assistant
- OpenAI Assistant will read all our ETL pipeline which is provided when we are generating the OpenAI assistant ID
- Usage Guidelines/Instructions: – Guide users on interacting with the OpenAI Assistant
- We are providing Instructions to our OpenAI Assistant to communicate with user
Step 6. Django/Flask/FastAPI API:
This step involves setting up an API using popular frameworks like Django, Flask, or FastAPI.
- Framework Selection: choice of the specific framework
- We are using Flask API to communicate with the OpenAI Assistant
- API Endpoints: available endpoints and their functionalities
- Configured the OpenAI Key in app1.py
- Configured the OpenAI Assistant ID in app1.py
- Store the Instruction file into variable we are using the variable below
- After the Configuration of Flask file run the app1.py file to start the Flask API Local Server
- Authentication: – Used for securing the API
- Handling Request and Response process
Step 7. Chat Frontend (Streamlit):
Represents the user interface for interacting with the system, built using Streamlit.
- Configurations: Configurations of Streamlit frontend
- Set your OpenAI API key into .env file
- User Interaction: Users will be able to query based on training data.
- Integration with Backend: – Frontend will be connect to the backend API.
- In the main.py file Provide the Flask API url endpoint to communicate with OpenAI Assistant
- Handle Request and Response from the User
Deliverables
- OpenAI Assistant Flask API
- Streamlit frontend
Tech Stack
- Tools used
- Visual Studio Code
- Language/techniques used
- Python, Flask, OpenAI
- Models used
- OpenAI Assistant
- Skills used
- Python, RestAPI, OpenAI API
What are the technical Challenges Faced during Project Execution
Finding the ETL pipelines and fine tuning the ETL pipelines
How the Technical Challenges were solved
Our approach to overcoming technical challenges involved an extensive internet search focused on ETL pipelines. We scoured various online resources, eventually identifying the most effective ETL pipelines available on GitHub.
To address each challenge systematically, we created individual files for each ETL pipeline. In the process, we meticulously fine-tuned and optimized each pipeline, documenting the specific tasks and functions within the respective files. This approach allowed us to provide detailed descriptions of the work performed for every ETL pipeline, ensuring a comprehensive understanding of the solutions implemented to tackle the technical hurdles encountered.
Business Impact
The business impact was substantial as the client efficiently analysed numerous ETL tool pipelines. Instant answers in a chat format replaced the time-consuming manual work that could take Data Engineers days or weeks. This streamlined process significantly enhanced productivity and responsiveness, reflecting a tangible improvement in operational efficiency for the client.
Project Snapshots
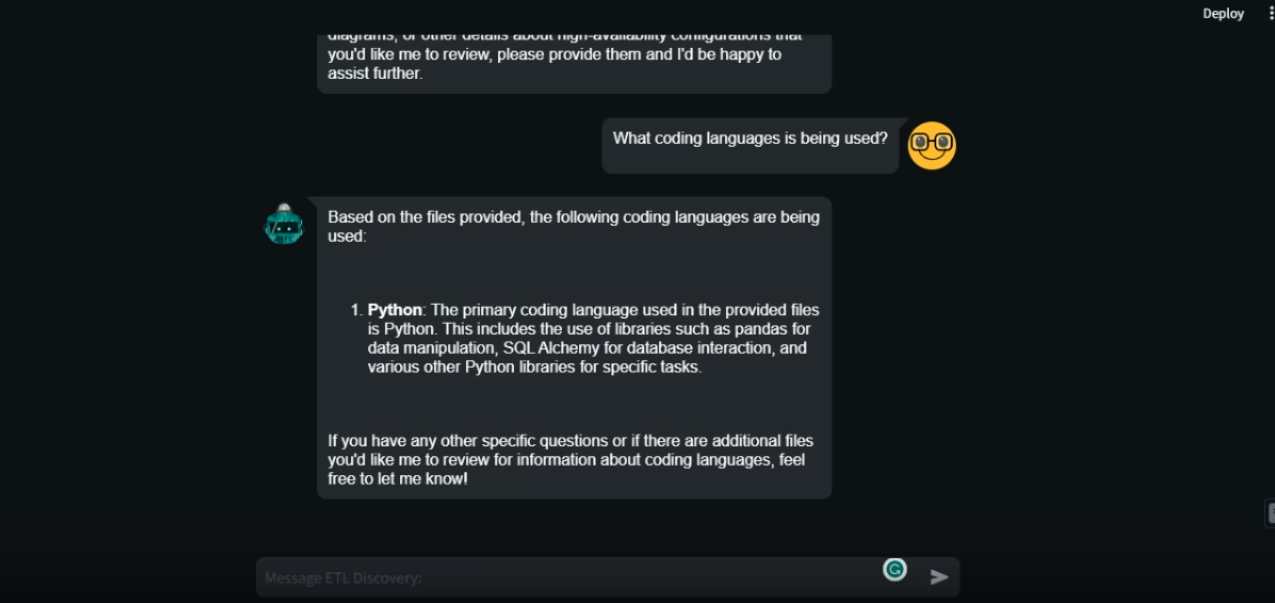

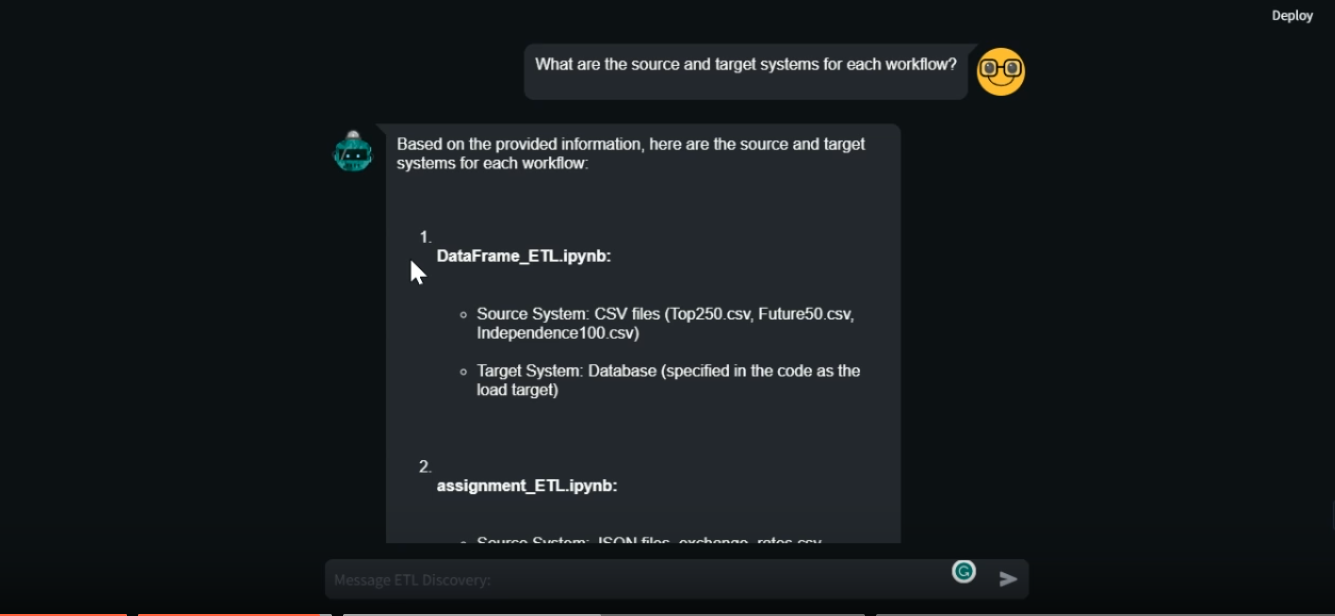
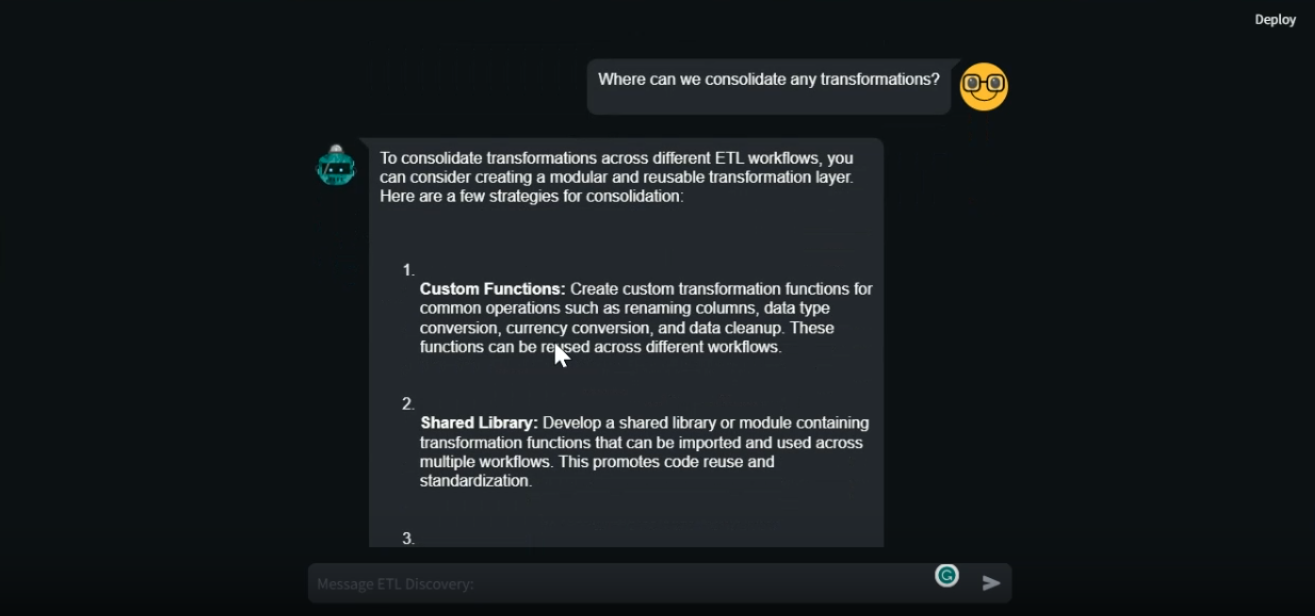
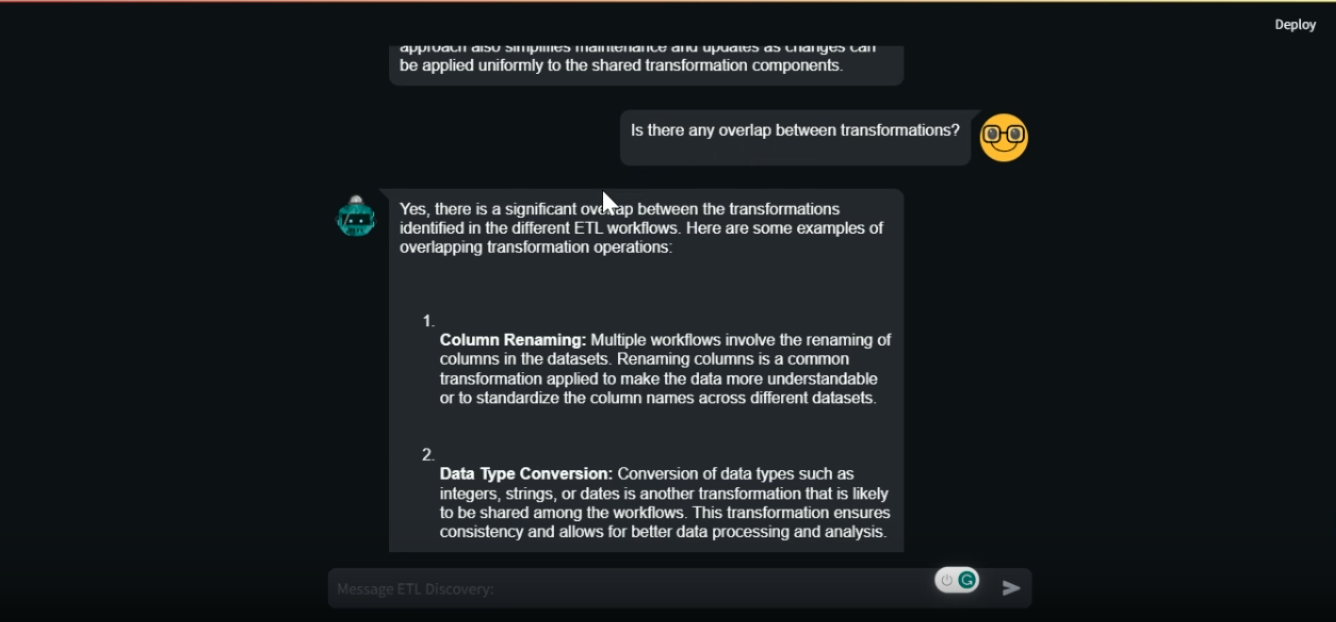
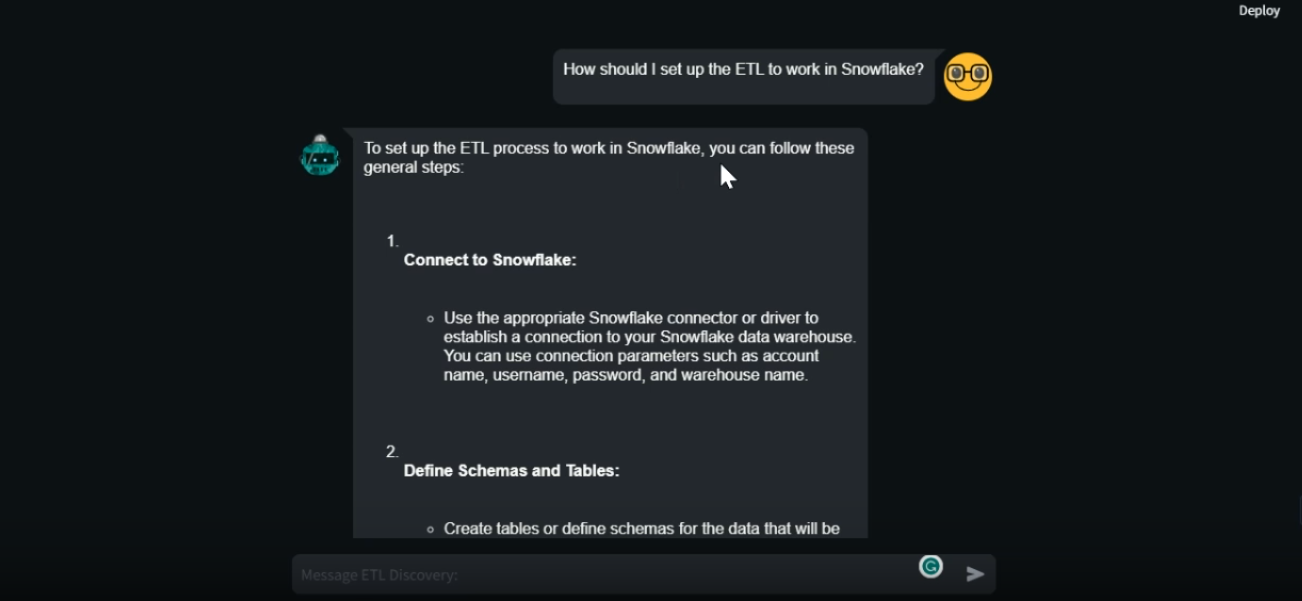
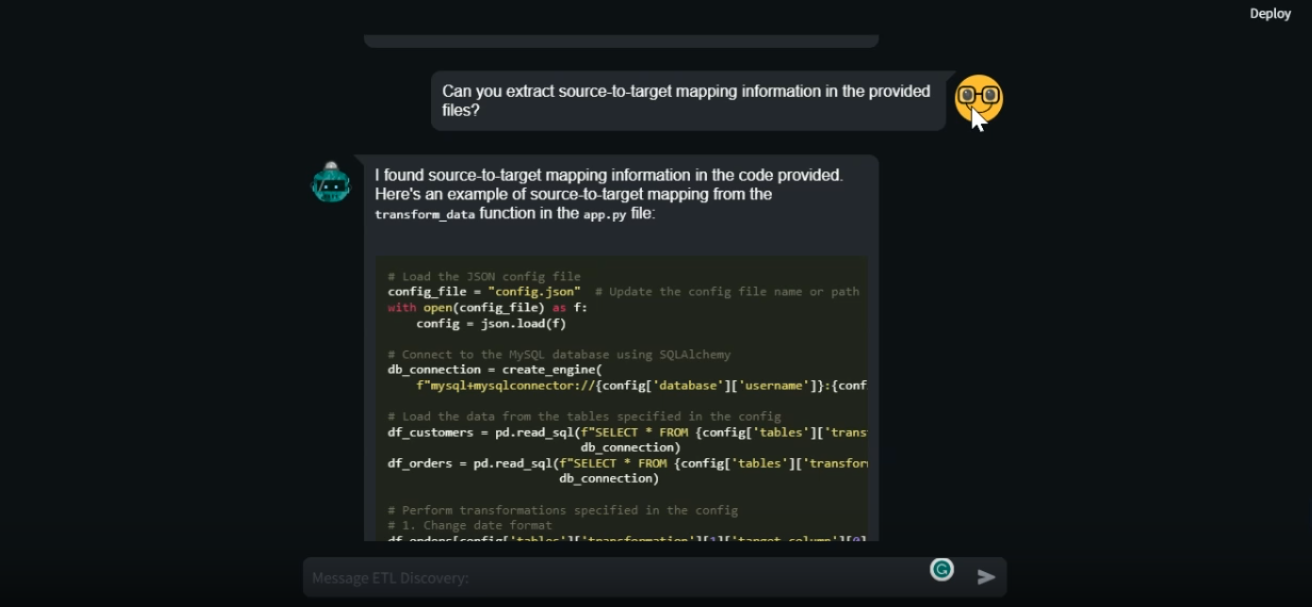
Assistant_creator.py
Main.py
Project Video
Project Demo Video link:- https://www.loom.com/share/5ee7d0835412474ea4aa3383af5a0814?sid=999739fc-e91a-4cda-a30e-9cd02957205f
Installation Walkthrough Video:-
Part 1 (Backend):- https://www.loom.com/share/338c4e09c90e453e83b86050d469d98b?sid=03299e7a-0699-464e-be2c-689a409ec01e
Part 2 (Frontend):- https://www.loom.com/share/8e7942f3a03e49889c6c70fba77f76b0?sid=eca0586f-b767-45fa-854d-853bca1890dc
Project GitHub Repository
- GitHub Link:- https://github.com/AjayBidyarthy/Rob-Sandberg-ETL
Summarize
Summarized: https://blackcoffer.com/
This project was done by the Blackcoffer Team, a Global IT Consulting firm.
Contact Details
This solution was designed and developed by Blackcoffer Team
Here are my contact details:
Firm Name: Blackcoffer Pvt. Ltd.
Firm Website: www.blackcoffer.com
Firm Address: 4/2, E-Extension, Shaym Vihar Phase 1, New Delhi 110043
Email: ajay@blackcoffer.com
Skype: asbidyarthy
WhatsApp: +91 9717367468
Telegram: @asbidyarthy










 to PowerBI")







