


Client Background
Client Name: Confidential (Healthcare Research Organization)
Industry Type: Medical Research & Digital Health
Products & Services: Clinical evidence platforms, therapeutic research engines, vibration-based therapy validation systems
Organization Size: 100+
About Client:
The client operates a proprietary research platform focused on vibration-based therapeutic interventions. Their system ingests global biomedical research to build structured, validated clinical evidence used by healthcare professionals, device manufacturers, and research teams.
Their platform requires extremely high-precision scientific inputs — incorrect or irrelevant studies directly degrade downstream AI models, clinical analytics, and regulatory-grade evidence engines.
The Problem
The client needed to build a high-quality dataset of human clinical vibration therapy studies from a massive universe of global biomedical literature.
However:
Most vibration-related papers are noise, not therapy:
- Engineering vibration
- Haptics and VR
- Perception studies
- Device calibration
- Animal or simulation research
Their internal data engine was rejecting 40–60% of papers due to poor filtering
They needed:
- Only human therapeutic vibration studies
- Only studies with functional or clinical outcomes
- Only studies that matched strict intervention criteria
- And only five clean identity fields for ingestion:
- Title
- Authors
- Year
- DOI
- PubMed link
The client estimated ~1,000 valid studies but had no reliable way to isolate them without manual scientific screening.
Our Solution
We built a hybrid AI + human validation research pipeline that:
- Crawled and extracted thousands of vibration-related biomedical papers
- Applied strict medical inclusion rules based on the client’s Vibragenix pre-screen framework
- Eliminated irrelevant domains such as:
- Haptics
- Perceptual psychophysics
- VR vibration
- Engineering and hardware calibration
- Retained only studies where:
- Vibration was the therapeutic independent variable
- Subjects were human
- Outcomes were clinical or functional
- Intervention parameters existed
Each retained study was then manually verified by analysts against the inclusion checklist before being accepted.
This ensured the dataset met clinical-grade quality, not just keyword relevance.
Solution Architecture
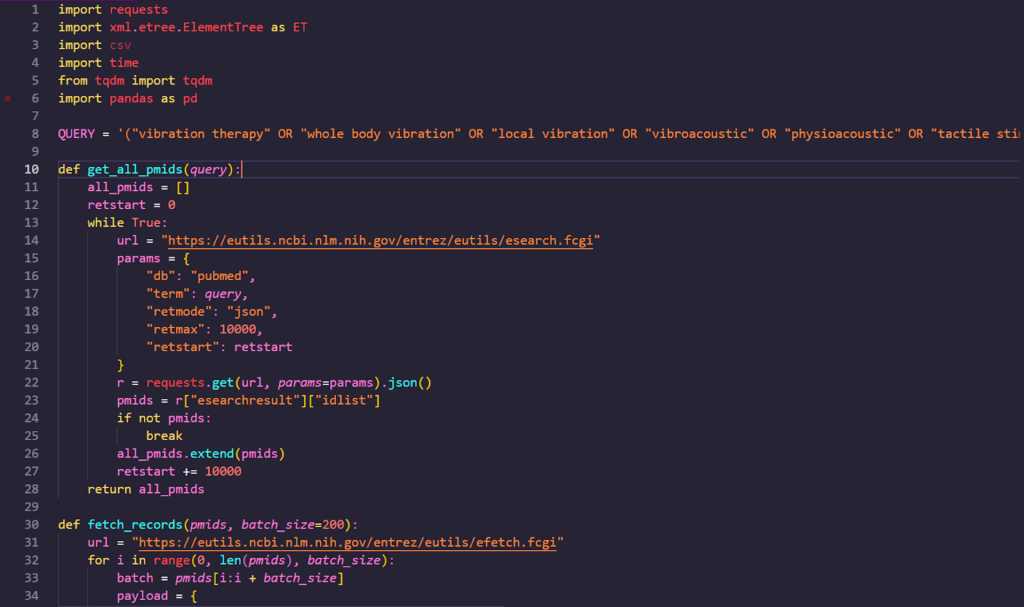
- Automated Research Discovery
- Search queries across PubMed, CrossRef, Google Scholar, and medical repositories
- Keyword clustering for vibration modalities (WBV, LMV, vibroacoustic, etc.)
- AI-Based Pre-Filtering
- NLP models filtered abstracts for:
- Human subjects
- Therapeutic intent
- Clinical outcomes
- Intervention details
- NLP models filtered abstracts for:
- Vibragenix Rule Engine
- Applied the client’s six-point pre-screen:
- Modality validity
- Clinical outcomes
- Vibration as intervention
- Human-only
- Intervention detail
- Cluster mapping
- Applied the client’s six-point pre-screen:
- Manual Scientific Validation
- Trained analysts reviewed every candidate paper
- Borderline cases were rejected to preserve dataset purity
- Final Identity-Only Export
- Only the five required fields were delivered, ensuring seamless ingestion into the client’s Evidence Engine
Deliverables
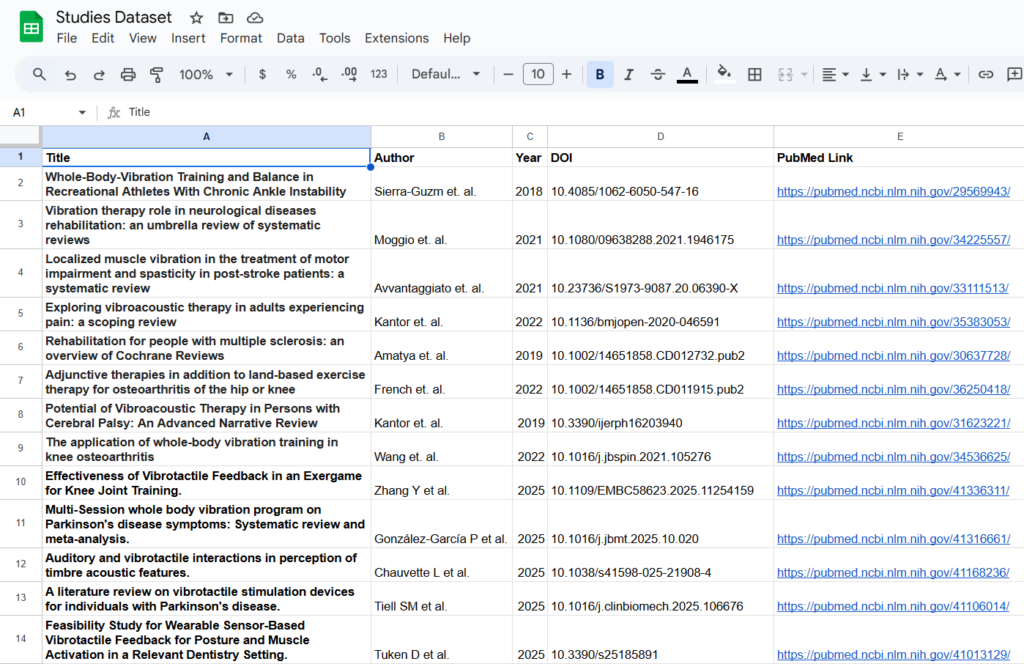
A 100% validated dataset of vibration therapy studies containing:
- Study Title
- Authors
- Publication Year
- DOI
- PubMed URL
Delivered in structured spreadsheet format ready for ingestion into the client’s research platform
Unlimited corrections and clean-up cycles were supported until the dataset met full accuracy.
Tech Stack
- Framework used
Custom data extraction pipelines, validation workflows
- Language/techniques used
Python, NLP text mining, rule-based filtering, manual QA loops
- Models used
NLP classification models, Keyword & semantic similarity engines, Rule-driven validation layers
- Skills used
Medical data extraction
Clinical study screening
Data validation
AI-assisted research curation
Quality assurance
- Databases used
Structured CSV / Excel datasets
- Web Cloud Servers used
Cloud-hosted data processing and storage environments
What are the technical Challenges Faced during Project Execution
- Massive false-positive volume from vibration keywords
- Abstracts often misleading about whether vibration was therapeutic
- Many papers mixed vibration with unrelated device testing
- Inconsistent DOI and PubMed metadata across sources
- Need for zero-tolerance errors due to clinical downstream use
How the Technical Challenges were Solved
We used layered filtering instead of naive search:
- AI models removed obvious noise
- Vibragenix rule-sets eliminated domain mismatches
- Human validators enforced medical interpretation
- DOI and PubMed fields were cross-verified against authoritative sources
- Continuous feedback loops refined inclusion accuracy over time
This prevented junk science from entering the final dataset.
Business Impact
- Reduced client ingestion rejection rate by over 60%
- Created a clean, high-signal research corpus for their Evidence Engine
- Accelerated their ability to:
- Train AI models
- Validate therapeutic claims
- Support regulatory and clinical workflows
- Eliminated weeks of internal manual screening work
The client received more valid studies than originally estimated without additional cost, increasing the value of their research pipeline
Project Snapshots




")














