


Client Background
Client: A leading financial firm in the USA
Industry Type: Financial services & Consulting
Services: Financial consultant
Organization Size: 100+
Project Objective
Project “Sentimental Analysis on Shareholder Letter of Companies” objective was to Predict the Sentiments columns Shareholder Letter in terms of Polarity and Subjectivity finally classification of data into positive, negative and neutral tone.
Project Description
The project ‘Sentimental Analysis on Shareholder Letter of US Companies’ task involved data cleaning on shareholder letters of different companies which includes lemmatization, lower case conversion, removing special character, \n , \t , punctuations, numbers & single character and tokenization. To generate polarity and subjectivity columns for the letter 1 & letter 2 columns using the Textblob library of NLTK. Based on the polarity categorizing it into positive, neutral & negative.
Our Solution
- Letter Text Length Variation
- Contraction mapping on dataset
- Replacing missing value with some neutral tone string like None so that cleaning doesn’t generate any issue.
- Data Cleaning and Preprocessing which involves :
i. Lemmatisation
ii. lower case conversion
iii. Removing Special character
iv. Removing \n , \t etc
v. remove punctuations, numbers & single character removal
vi. forming list of letter data using tqdm
- Tokenization and word count.
- Used Textblob Library which is part of NLTK for Sentiment analysis.
- Created Polarity and Subjectivity column for the Letter1 & Letter2 columns
- Based on the polarity of letter 1 created a letter1_type column with values “positive” , “neutral” & “negative” category.
Project Deliverables
- Output iPython File
- Preprocessed Dataset
Tools used
● Jupyter Notebook
● Anaconda
● Notepad++
● Sublime Text
● Brackets
● Python 3.4
Language/techniques used
- Python
- Machine Learning
- NLP (Natural Language Processing)
Models used
My project ‘Sentimental Analysis on Shareholder Letter of Companies’ developed with a software model which makes the project high quality, reliable and cost effective.
● Software Model : Waterfall Model
● For Project ‘Sentimental Analysis on Shareholder Letter of US Companies’ is a Waterfall Model as our model is not forming the loop from end to the start using Textblob which predicts Sentiments, Polarity and Subjectivity as the output following the Waterfall Model.
Skills used
- Pandas Operations
- Data Chunking and Integration
- Data Visualization
Databases used
No Database is used to complete this project.
Web Cloud Servers used
No Web cloud Server was required for this work.
What are the technical Challenges Faced during Project Execution
I have worked before on tasks similar to this so there were no challenges faced but the data cleaning was a bit different and required time to complete.
How the Technical Challenges were Solved
As Discussed no technical Challenges were faced during this project.
Project Snapshots

Figure 1: Input Data Schema

Figure 2: Output Data Schema

Figure 3: Sample Input Dataset
figure 3 is pandas dataframe which was fetched from google cloud database there were 7 columns and 13290 rows.
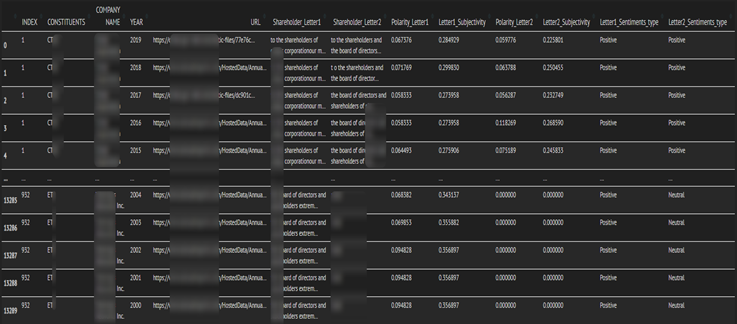
Figure 4: Sample Output Dataset
figure 4 is output pandas dataframe after data cleaning and modeling of sentiment identification there are 13 columns and 13290 rows.

Figure 5: Sentiments assignment based on polarity
figure 5 represents the identification of sentiments and tone based on polarity and subjectivity. polarity>0 then sentiment type is positive, if the polarity<0 sentiment type is negative and if the polarity=0 sentiment type is neutral.

Figure 6: Histogram Representation of Length of Shareholder Letter 1
figure 6 is histogram plot between length of shareholder letter 1 among the final output dataset.
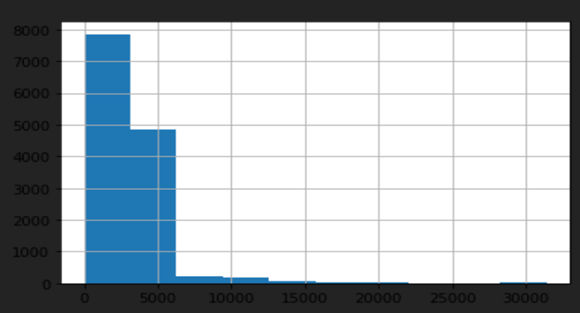
Figure 7: Histogram Representation of Length of Shareholder Letter 2
figure 7 is Histogram plot between length of shareholder letter 2 among the final output dataset.

Figure 8: Flow Chart















 with custom data connectors to manage CRM database")



