


Client Background
Client: A Leading News Intelligence & Analytics Startup in the USA
Industry Type: Media Intelligence / Enterprise SaaS
Products & Services: News aggregation, content enrichment, enterprise insights, and trend analysis tools
Organization Size: 100+
The Problem
The client aimed to build a scalable, automated news aggregation and intelligence platform powered by Elasticsearch. However, they faced the following key challenges:
- The existing crawler failed to consistently ingest structured and unstructured content from HTML/XML sources.
- Inability to scale to millions of articles per run or add new sources dynamically.
- Lack of enrichment layers (e.g., categories, sentiment, tagging) reduced the effectiveness of analytics and personalization.
- No operational monitoring or visibility into ingestion success/failure.
- No centralized search, clustering, or recommendation framework in place.
These issues significantly slowed down product development and limited the platform’s potential to deliver timely, relevant insights to enterprise clients.
Our Solution
We delivered a full-stack technical solution that resolved the issues and accelerated product delivery:
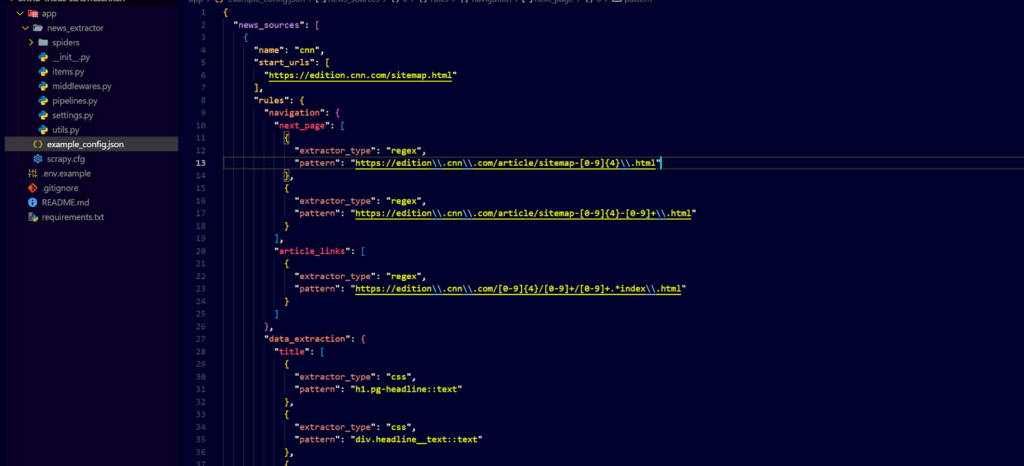
- Crawler Debugging and Enhancement: Fixed the broken universal crawler (HTML/XML), enhanced it to support large-scale ingestion (millions of articles), and deployed it on a cloud VM for continuous execution.
- Automated Data Ingestion: Used Scrapy framework to enable automated, scalable fetching of news data from dynamic and static sources.
- Elasticsearch Integration: All crawled content was indexed into Elasticsearch with proper schema mappings for scalability and querying.
- Data Enrichment: Implemented tagging, categorization, and author metadata enrichment. Extended enrichment pipeline for future use with sentiment analysis and topic modeling.
- Monitoring Layer: Set up logging and alerts to monitor crawler health and ingestion success/failure.
- Scalable Infrastructure: Designed system to support easy addition of new sources, using a plug-and-play source ingestion model.
Solution Architecture
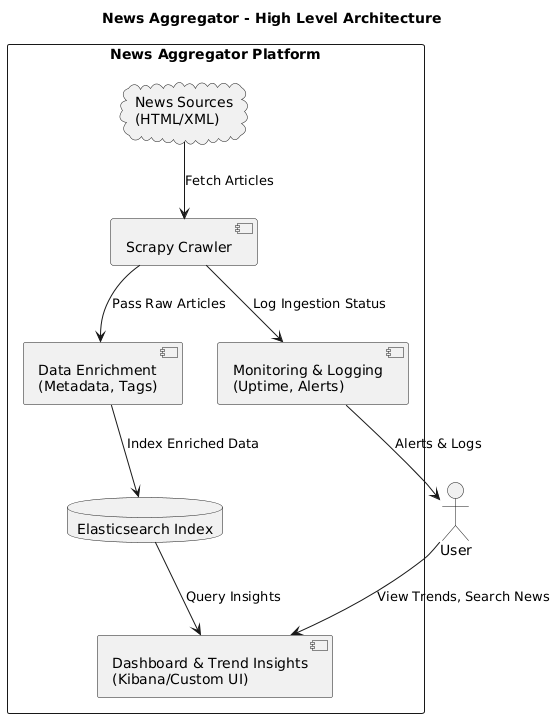
Crawler: Custom-built Scrapy crawler capable of parsing HTML and XML feeds
Indexing: Content stored and indexed in Elasticsearch for fast search and analytics
Data Enrichment: Tags, categories, and article metadata enhanced using NLP modules
Analytics & Aggregation: Elasticsearch aggregations to enable trend discovery and insight generation
Deployment: Ubuntu-based cloud VM to host the crawler and support continuous ingestion
Monitoring: Logging and alerting system for crawler performance and failure detection
Deliverables
- Fully functional, scalable HTML/XML crawler
- Ingestion pipeline connected to Elasticsearch
- Article metadata enrichment for improved search & personalization
- Monitoring dashboard and alerts for ingestion jobs
- Documentation for future enrichment modules and source onboarding
Tech Stack
Tools Used:
- Scrapy, Elasticsearch, Kibana, Uptime Robot, Logtail
Language/Techniques Used:
- Python, XPath, NLP tagging, REST APIs
Models Used:
- Planned sentiment & topic modeling (future extension)
Skills Used:
- Crawler optimization, Elasticsearch tuning, DevOps (VM deployment), Data Engineering
Databases Used:
- Elastic Cloud (NoSQL index-based data store)
Web Cloud Servers Used:
- Cloud Virtual Machine (AWS), Elastic Cloud
What are the technical Challenges Faced during Project Execution
Crawler was unable to handle dynamic sites and failed silently
Lack of scale and poor memory management for high-volume crawling
Elasticsearch indexing failed on malformed or inconsistent data
Manual source onboarding process caused bottlenecks
No error visibility or alerting mechanisms for ingestion jobs
How the Technical Challenges were Solved
Refactored crawler to handle dynamic sites, structured/unstructured feeds, and memory-intensive workloads
Used asynchronous crawling and batching for performance optimization
Built unified schema mapping to index enriched data into Elasticsearch without errors
Modularized source handlers for plug-and-play addition of new news feeds
Set up logging, alerting, and basic uptime monitoring to ensure operations visibility
Business Impact
10x scale-up in article ingestion volume
100% improvement in crawler reliability and uptime
Faster customer onboarding with dynamic source integration
Richer, more relevant insights and analytics via enriched metadata
Reduced manual intervention and faster time-to-market for product features
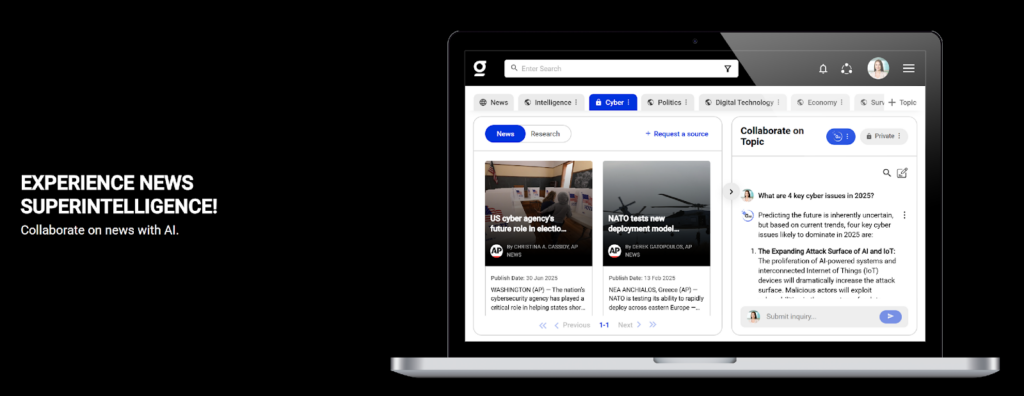
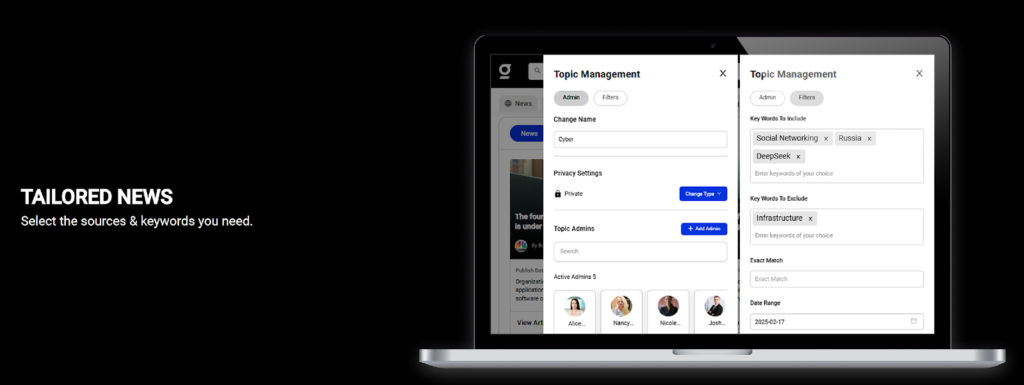
Project Snapshots
















 Tool using BERT")



