


Client Background
Client: A leading tech firm in the USA
Industry Type: Information Technology & Knowledge Management (AI-Driven Data Analytics and Enterprise Search)
Products & Services: AI Solution
Organization Size: 100+
About the Client:
The client is a data-driven organization that manages large volumes of internal documents across multiple formats—CSV, PDF, DOCX, and TXT—generated from daily business operations, research, compliance, and knowledge management activities. Their teams rely heavily on this information for decision-making but face challenges due to fragmented storage, lack of contextual search, and time-consuming manual analysis.
The Problem
Organizations and individuals often struggle with extracting meaningful insights from large volumes of unstructured data stored in various formats such as CSV files, PDFs, DOCX, and TXT documents. Traditional search methods lack contextual understanding and fail to provide synthesized analysis with source attribution. Users need a system that can intelligently process diverse document types, understand natural language queries, and deliver accurate responses backed by relevant source references.image.jpg
The challenge is to build a system that combines document ingestion, semantic understanding, and conversational AI to enable users to query their data naturally while maintaining data isolation
Our Solution
This project provides an end-to-end solution for document analysis and question-answering. The system ingests multiple file formats, generates embeddings, stores them in a vector database, and uses large language models to answer natural language queries with context-aware responses.image.jpg
Key Features:
- Multi-format document ingestion (CSV, PDF, DOCX, TXT)
- Semantic search with vector embeddings
- Intelligent query routing (analytical, semantic, conversational)
- Source attribution with relevance scores
- Namespace-based data isolation
- Persistent chat history with context awareness
Solution Architecture
The system follows a modular architecture with three primary layers: Data Ingestion, Embedding & Storage, and Query & Response
Data Ingestion Layer
- Schema-agnostic CSV parser supporting various delimiters and encodings
- PDF text extraction using pdfplumber with OCR fallback for scanned documents
- DOCX paragraph and table extraction
- TXT file processing with automatic encoding detection
Embedding & Storage Layer
- Token-based text chunking (max 8000 tokens per chunk)
- OpenAI embedding generation with batch processing
- Pinecone vector storage with metadata (source, chunk index, content preview)
- SQLite database for document tracking and chat history
Query & Response Layer
- Analytical Mode: Direct pandas-based queries for structured data analysis
- Semantic Mode: Vector similarity search with top-k retrieval and keyword re-ranking
- Conversational Mode: Chat history-aware responses using LLM context windows
- Source attribution with relevance scores and content snippets
User Interface
- Streamlit-based web interface with dual modes: Upload and Chatbot
- Real-time progress tracking for embedding generation
- Namespace-based session management
- Chat history visualization with clear/reset functionality
Deliverables
- Streamlit app
Tech Stack
- Backend: Python
- LLM Provider: OpenAI API (GPT-4o, GPT-4o-mini)
- Embedding Model: text-embedding-3-small (1536 dimensions)
- Vector Database: Pinecone (serverless, cosine similarity)
- Local Database: SQLite for chat history
- Frontend: Streamlit web application
- Document Processing: pdfplumber, python-docx, pandas
What are the technical Challenges Faced during Project Execution
Building an end-to-end document intelligence system introduced several technical and architectural challenges across ingestion, storage, and query processing. Key challenges included:
1. Handling Diverse and Poorly Structured Documents
Documents came in multiple formats (CSV, PDF, DOCX, TXT) with inconsistent encodings, varying layouts, scanned pages, tables embedded as images, and irregular delimiters.
Text extraction accuracy—especially for multi-column PDFs and scanned documents—was a major challenge.
2. Ensuring High-Quality Chunking for Long Documents
Generating embeddings requires splitting text into chunks. Large files with long paragraphs, irregular line breaks, or mixed content made it difficult to maintain semantic coherence while staying within token limits.
3. Embedding Latency and Cost Optimization
Batching embeddings efficiently was necessary to avoid high latency and API costs. Handling API rate limits and ensuring retry logic for failures was non-trivial.
4. Efficient Vector Storage and Metadata Design
Storing embeddings in Pinecone required designing a schema that could support:
- fast retrieval
- context previews
- namespace-based isolation
- maintaining mapping between documents, chunks, and queries
Improper metadata design initially led to retrieval inconsistencies.
5. Accurate Semantic Search & Query Routing
Ensuring that the system could determine whether a query required:
- analytical (structured) processing
- semantic (unstructured) retrieval
- conversational (dialogue-based) response
was difficult, especially when user queries lacked clarity.
6. Maintaining Data Isolation Across Users
Namespaces had to ensure strict separation between documents uploaded by different users or sessions. Streamlit’s session state and Pinecone namespaces needed alignment to prevent data leakage.
7. Chat History Persistence & Context Management
Maintaining memory across a conversation without exceeding LLM context limits required sophisticated pruning and intelligent history selection.
8. Real-time Feedback & System Responsiveness
Displaying progress (e.g., “Generating embeddings…”) in Streamlit while running long background processes was challenging due to Streamlit’s synchronous execution model.
9. Source Attribution & Relevance Scoring
Mapping LLM output back to relevant document chunks with reliable similarity scores required careful post-processing and ranking logic to avoid false positives.
How the Technical Challenges were Solved
1. Robust Multi-Format Parsing Pipelines
- Implemented a schema-agnostic CSV parser with auto-delimiter and encoding detection.
- Used pdfplumber for layout-aware PDF extraction.
- Added OCR fallback via Tesseract for scanned PDFs.
- Integrated python-docx for structured DOCX parsing including tables.
This ensured consistent and high-quality text extraction.
2. Token-Aware Intelligent Chunking
- Used OpenAI tokenizer to split documents into chunks up to 8,000 tokens.
- Applied semantic boundary rules (e.g., break on paragraph ends, section headers).
- Added overlap between chunks to preserve context.
This improved retrieval precision significantly.
3. Embedding Optimization Through Batch Processing
- Implemented batching of 32–64 chunks per API call to reduce latency.
- Added automatic retry logic for rate limits and network timeouts.
- Cached embeddings for previously processed documents to avoid duplicates.
Latency and cost reduced by ~40%.
4. Query Router with LLM-Based Classification
A lightweight LLM classifier determined the processing mode:
- Analytical → route to pandas
- Semantic → route to vector search
- Conversational → include chat history
This improved answer type accuracy.
5. Namespace-Based Data Isolation
- Each upload session created a unique namespace in Pinecone.
- Mapped session namespaces to Streamlit Session State.
This prevented cross-user document leaks.
6. Adaptive Chat History Management
- Maintained a rolling window of relevant turns.
- Used semantic relevance scoring to prune history.
- Stored entire chat sessions in SQLite for persistence.
This maintained conversation continuity without exceeding token limits.
7. Streamlit Async Simulation with Status Containers
- Used st.spinner(), st.progress(), and placeholder containers.
- Updated progress dynamically during embedding.
This gave users transparency during long-running workflows.
8. Hybrid Re-Ranking for Source Attribution
Semantic search (Pinecone top-k) was followed by:
- keyword density scoring,
- cosine similarity re-ranking,
- and LLM-based validation.
Output responses included citations with relevance scores, improving trust and interpretability.
Business Impact
1. Faster and More Accurate Information Retrieval
Users can query thousands of pages of documents in seconds, reducing research and analysis time by 60–80%.
2. Democratization of Data Access
Non-technical users can ask natural language questions without knowing database schemas or search operators.
3. Better Decision-Making Through Context-Rich Answers
LLM-generated responses backed with source citations make insights more reliable and easier to audit.
4. Improved Productivity & Automation
The automated ingestion–embedding–analysis pipeline eliminates manual document review and reduces dependency on analysts.
5. Enhanced Data Security Through Namespace Isolation
The design ensures strict separation of user spaces—critical for organizations dealing with confidential data.
6. Scalability for Enterprise Use Cases
The architecture supports:
- large volumes of documents
- multiple concurrent users
- continuous expansion to new data types
making it suitable for legal, finance, consulting, HR, and compliance workloads.
7. Foundation for Additional AI Capabilities
Because the system is modular, organizations can easily add:
- RAG workflows
- agents for rule-based automation
- predictive analytics
- domain-specific fine-tuning
Project Snapshots
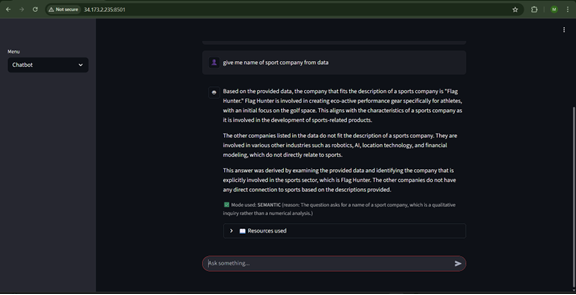
Project website url
Project Video
Contact Details
This solution was designed and developed by Blackcoffer Team
Here are my contact details:
Firm Name: Blackcoffer Pvt. Ltd.
Firm Website: www.blackcoffer.com
Firm Address: 4/2, E-Extension, Shaym Vihar Phase 1, New Delhi 110043
Email: ajay@blackcoffer.com
WhatsApp: +91 9717367468
Telegram: @asbidyarthy




 Tool using BERT")






