


Sentiment Analysis
Sentiment analysis is the process of determining whether a piece of writing is positive, negative or neutral. The below Algorithm is designed for use on Financial Texts. It consists of steps:
Cleaning using Stop Words Lists
The Stop Words Lists (found here) are used to clean the text so that Sentiment Analysis can be performed by excluding the words found in Stop Words List.
Creating dictionary of Positive and Negative words
The Master Dictionary (found here) is used for creating a dictionary of Positive and Negative words. We add only those words in the dictionary if they are not found in the Stop Words Lists.
Extracting Derived variables
We convert the text into a list of tokens using the nltk tokenize module and use these tokens to calculate the 4 variables described below:
- Positive Score: This score is calculated by assigning the value of +1 for each word if found in the Positive Dictionary and then adding up all the values.
- Negative Score: This score is calculated by assigning the value of -1 for each word if found in the Negative Dictionary and then adding up all the values. We multiply the score with -1 so that the score is a positive number.
- Polarity Score: This is the score that determines if a given text is positive or negative in nature. It is calculated by using the formula:
- Polarity Score = (Positive Score – Negative Score)/ ((Positive Score + Negative Score) + 0.000001)
- Range is from -1 to +1
- Subjectivity Score: This is the score that determines if a given text is objective or subjective. It is calculated by using the formula:
- Subjectivity Score = (Positive Score + Negative Score)/ ((Total Words after cleaning) + 0.000001)
- Range is from 0 to +1
Sentiment score categorization
This is determined by grouping the Polarity score values in the following groups.
- Most Negative: Polarity Score below -0.5
- Negative: Polarity Score between -0.5 and 0
- Neutral: Polarity Score equal to 0
- Positive: Polarity Score between 0 and 0.5
- Very Positive: Polarity Score above 0.5
Analysis of Readability
Analysis of Readability is calculated using the Gunning Fox index formula described below.
- Average Sentence Length = the number of words / the number of sentences
- Percentage of Complex words = the number of complex words / the number of words
- Fog Index = 0.4 * (Average Sentence Length + Percentage of Complex words)
Average Number of Words Per Sentence
The formula for calculating is:
- Average Number of Words Per Sentence = the total number of words / the total number of sentences
Complex Word Count
Complex words are words in the text that contain more than two syllables.
Word Count
We count the total cleaned words present in the text by
- removing the stop words (using stopwords class of nltk package).
- removing any punctuations like ? ! , . from the word before counting.
Syllable Count Per Word
We count the number of Syllables in each word of the text by counting the vowels present in each word. We also handle some exceptions like words ending with “es”,”ed” by not counting them as a syllable.
Personal Pronouns
To calculate Personal Pronouns mentioned in the text, we use regex to find the counts of the words – “I,” “we,” “my,” “ours,” and “us”. Special care is taken so that the country name US is not included in the list.
Passive Words
Passive Words are the Auxiliary verbs followed by a word ending in “ed” or one of 200 irregular verbs present in the Past form column in this link.
Auxiliary verbs are – auxiliary verb variants of “to be” including: “to be”, “to have”, “will be”, “has been”, “have been”, “had been”, “will have been”, “being”, “am”, “are”, “is”, “was”, and “were”.
Average Word Length
Average Word Length is calculated by the formula:
Sum of the total number of characters in each word/Total number of words
Bog Index
- Sentence Bog + Word Bog – Pep
- Bog = Anything that distracts from reading.
- Pep = anything that makes reading interesting.
- Sentence Bog = Average Sentence Length.
Calculated by a Software package called Style Writer designed to identify English attributes and calculate the score.
Uncertainty
Measure of words pertaining to uncertainty in a sentence.
It is calculated by assigning the value of +1 for each word if found in the Uncertainty Keyword Dictionary.
Dictionary – Loughran and McDonald (2011) Uncertainty
Forward Looking Statement
This measure is calculated by measuring the statements which predict or project something in future events or possibilities and can be calculated by counting such statements.
Risk Factor
Calculating words that are related to risk factors and assigning the value of +1 for every word found in the dictionary and adding up the values.
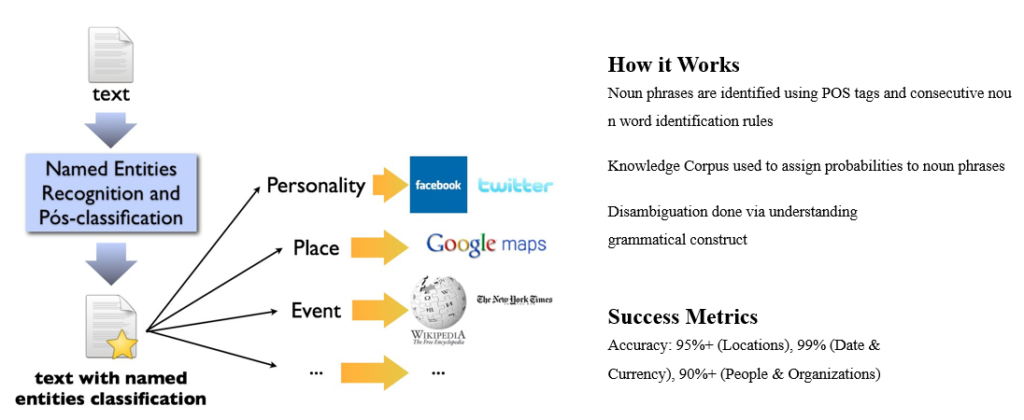
Specificity – Named Entity Recognition (NER)
Using a Named Entity Recognition (NER) approach to find names of persons, places, and organizations.
- Named Entity Recognition will be used to identify words pertaining to people, location, currency, and dates from the text corpus.
- The Named Entity Recognition plays a vital role in identifying the important keywords, features in any given sentence, and also used for summarization of any sentence or article.
- It automatically scans the documents and reveals which are the major people, organizations, and places discussed in them.
Input
Document, Paragraphs i.e News Articles in this case
Output
Names of places, people, dates, currency amounts, locations in the article.
Measures
- Named Entity: This measure contains all the Named Entities i.e. the names of places, people, dates, currencies used in the text. It gives a rough idea about what things are being talked about in the text.
- NER Count: This score tell is assigned by the values of +1 for each named entity that is recognized in the text and adding up all the values.
- NER Percentage: The NER Percentage is calculated by the following formula
- NER % = (NER Count / Word Count) *100
Topic Modeling
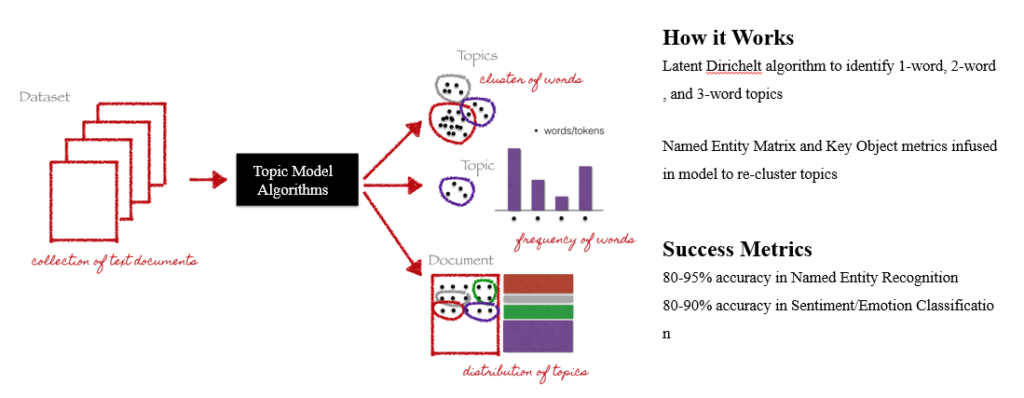
- Topic Modelling is a statistical modelling using deep learning techniques to discover the abstract topics that occur in a collection of documents.
- Its builds a topic per document and words per topics model to discover topic of the document or articles.
- In our topic models we will be focused on news articles publishing news mainly covering areas of “startups”, “entrepreneur”, innovation”, “technology”, ”coworking space”, “startup business”.
Input
Documents, Articles, i.e., New Articles in this case.
Output
Set of words that are most likely to describe the topic within the document or the article.
Measures
- Topic Words: This measure contains the topic words found in the text. Topic words are found by using the LDA algorithm to and tell use the combination or a set of words the text is talking about.
- Word Count: The Topics Words that are found using the LDA algorithm are search though the whole text and a value of +1 is assigned each time the topic word is found and then added all values. This measure gives the count of topic words so we get to know how much emphasis is being made to the topic words found.
Statistical Model used
LDA (Latent Dirichlet Allocation)
Working of Model
The LDA model words as

W – Each word in a topic
Z – Topic
N – Single document
M – Collection of Documents
α – per-document-topic distributions
β – per-topic word distribution
The LDA algorithm works on BOW or the bag of words approach that doesn’t not has any syntax to its sentences but still can be used to tell the topic of the words.
It assumes that every topic Z is made up of a collection of words W with each word being assigned a probability that it belongs to a specific topic Z and each document N is made up of several topics Z with varied percent of several topics covered in each document.
The process is done for all the documents taking out probabilities for each word belonging to some topic we come up with a final model of the words and their relation to the topics covered in the documents.
On applying this model to the corpus of words in a document we have, we get the topics that are covered in the document i.e. the words associated with it.
Application of Topic Modelling
Topic Modelling is a useful method that enhances a researcher’s ability to interpret large amount of text documents for information. It is frequently used as a text-mining tool for discovery of hidden structure in a text body.
The topic modelling is used to identify the hidden topic and the strongly related words that are associated with any documents.
The Topic modelling along with Sentiment analysis is a very powerful measure that can be used to explore and summarize any article that has been covered in the news.
Deep Learning
The deep learning model is applied to the news data to get more details insights about the data.
In this deep learning model, we prepared a set of all possible keywords that are related to the start-up, entrepreneur environment, and the model is prepared to check for the occurrence of each keyword in the throughout the document of news.
Any keywords from the prepared set found in the text document we add a weight of +1 to that keyword and after iterating through all the keywords add up all the weights to find the total contribution of that keyword to the news text.
Input
Document or set of news text documents.
Output Measures
The weight and contribution of each keywords related to the research topics.












")






