


Client Background
Client: A leading financial services firm in the USA
Industry Type: Financial Services & Market Intelligence (Rent-to-Own and Consumer Finance Analytics)
Products & Services: Financial services Solution
Organization Size: 100+
About the Client:
The client is a market intelligence and analytics-focused organization operating within the Rent-to-Own (RTO) and broader consumer finance ecosystem. They support investors, strategy teams, and industry analysts who rely on deep, historical, and real-time insights to evaluate market trends, competitive dynamics, pricing strategies, and regulatory developments.
The Problem
Organizations in the Rent-to-Own (RTO) and consumer finance ecosystem struggle to aggregate, maintain, and analyze large volumes of fragmented industry data. Critical information—such as SEC filings, earnings call transcripts, franchise disclosure documents, industry magazines, podcasts, and YouTube content—is scattered across multiple sources, often unstructured, and updated on inconsistent schedules.
As a result, decision-makers lack:
- A centralized source of truth for 20+ years of industry-relevant data
- Automated mechanisms to capture ongoing market changes
- Integrated analysis tools capable of generating contextual insights
- Real-time monitoring of websites, pricing, products, and competitive activities
This leads to slow research cycles, incomplete insights, and an inability to quickly respond to changing market conditions across key RTO players such as Rent-A-Center, Aaron’s, Buddy’s, FlexShopper, Katapult, and others.
Our Solution
We propose an end-to-end automated intelligence system built entirely on n8n, integrating large-scale data collection, continuous monitoring, and AI-driven analysis. The solution captures 20 years of historical industry data, automates daily/weekly updates across all channels, and makes the complete knowledge base queryable through an OpenAI-powered NLP interface.
The system delivers:
- A unified data lake stored in AWS S3
- Automated extraction from SEC filings, FDDs, APRO magazines, podcasts, and YouTube channels
- Daily monitoring of websites, promotions, pricing, and products
- A vector-database layer enabling semantic search and deep insights
- An API-based customer query interface powered by OpenAI
- Full workflow management, error handling, and reporting inside n8n
This creates a scalable, low-maintenance competitive intelligence engine for the entire RTO industry
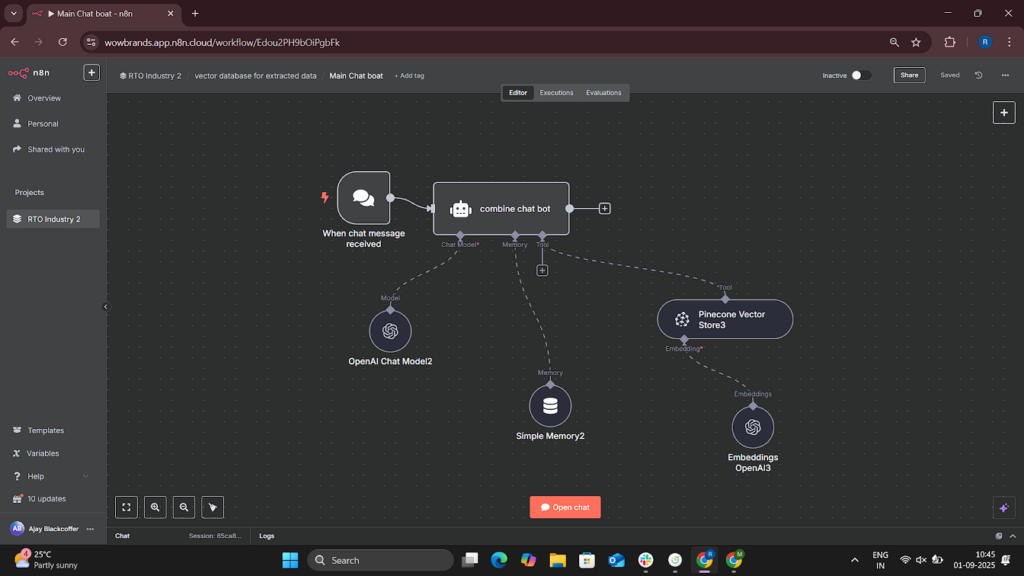
Solution Architecture
Phase 1: Collect & Aggregate Industry Knowledge
- Financial Data (M1.1) – Scrape 20 years of weekly SEC filings for RCII, AAN, FPAY, KPLT, and FRG’s Buddy’s segment using HTTP Request nodes; store raw + processed data in S3.
- Earnings Call Transcripts (M1.2) – Retrieve transcripts via APIs/web scraping, convert to text, and upload to S3.
- Franchise Disclosure Documents (M1.3) – Collect and digitize FDD filings; upload and index through n8n.
- APRO Magazine OCR (M1.4) – Extract text from 36+ issues using OCR nodes; save to S3 for later analysis.
- Podcast Ingestion (M1.5) – Monitor RSS feeds daily, download episodes, and generate transcripts.
- YouTube Monitoring (M1.6) – Automatically fetch video metadata, transcripts, and updates from key RTO channels.
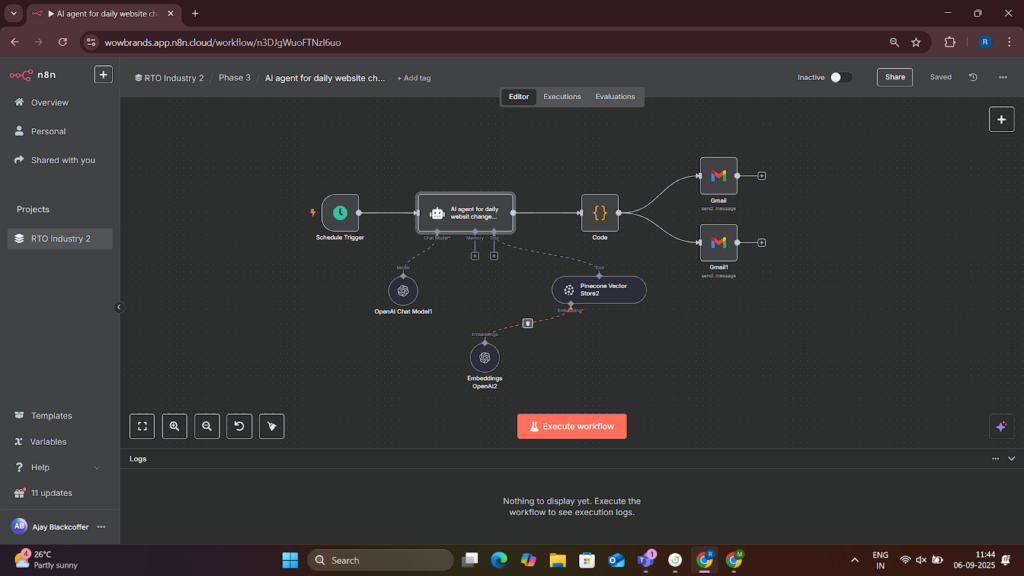
Phase 1.5: Automated Data Monitoring Agents
- Monitoring Workflows (M1) – Scheduled triggers track new financial data, videos, podcasts, and SEC updates.
- Website & Pricing Monitoring (M1.7) – Scrape daily changes from RTO websites using HTML Extract and HTTP Request nodes.
- Daily Trend Report (M1.5.3) – Email stakeholders automated daily summaries with detected changes.
Phase 3: NLP Integration & Query System
- Vector Database (M3.1) – Generate embeddings using OpenAI; store in Pinecone/Weaviate for semantic search.
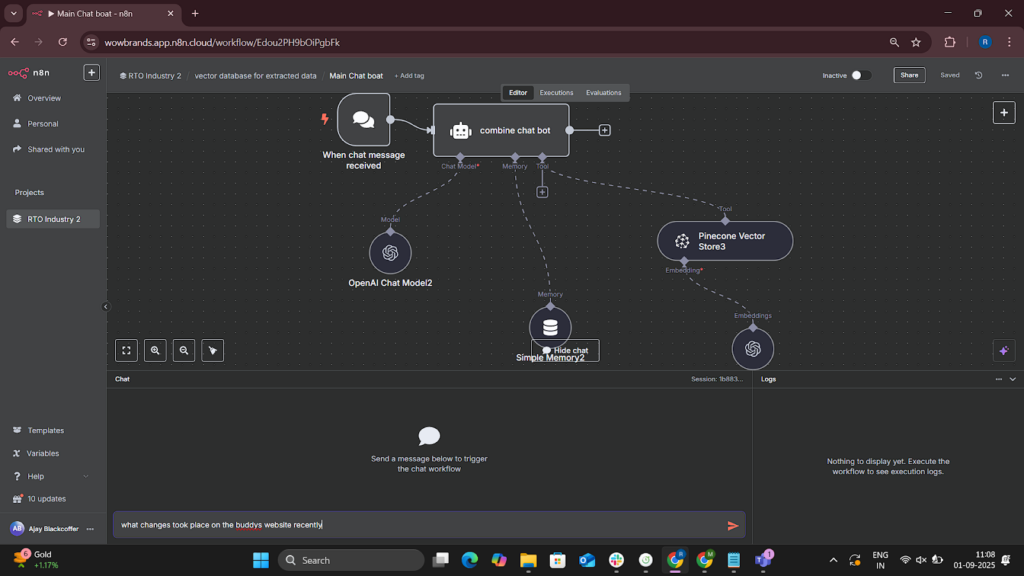
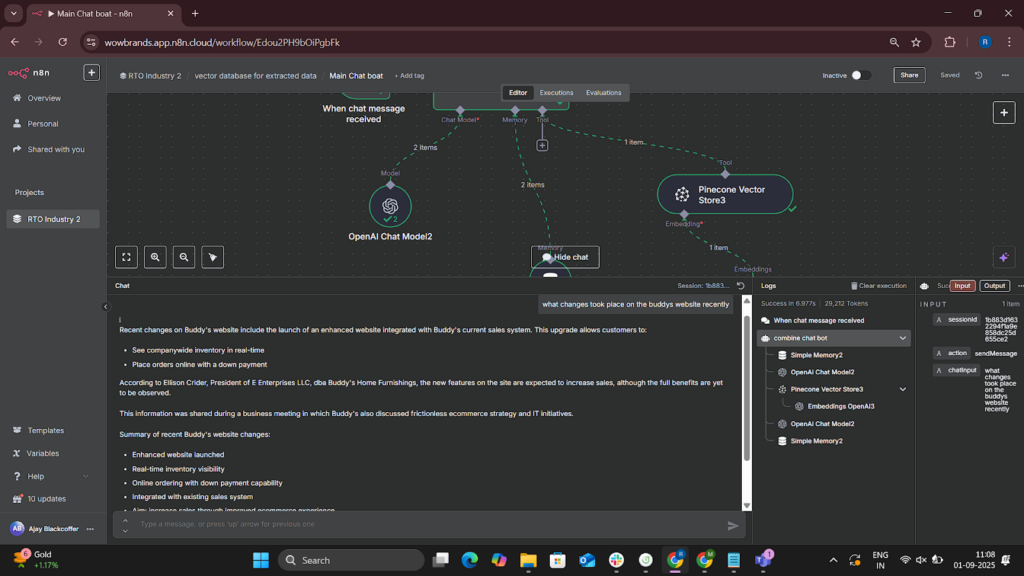
- OpenAI Integration (M3.2) – Run industry-focused NLP queries such as “What changed in RTO pricing this week?”
- Workflow Management (M3.3) – Central monitoring, logging, and error notification for all n8n processes.
- Customer Query Interface (M3.4) – Webhook-based API allowing users to query the entire knowledge base; integrated with a simple frontend.
Deliverables
1. Data Infrastructure
- AWS S3-based structured and unstructured data lake
- 20 years of SEC filings, financial time series, transcripts, FDDs, magazines, podcasts, and YouTube data
- Daily website monitoring dataset (pricing, promotions, product changes)
2. n8n Workflows
- Scraping workflows for SEC, YouTube, podcasts, websites
- OCR workflows for APRO magazines
- Scheduled monitoring agents (daily/weekly)
- Automated reporting and alerting workflows
- Error-handling, logging, and workflow dashboards inside n8n
3. AI Layer
- Vector database populated with embeddings of all documents
- OpenAI-powered semantic search and NLP query engine
- API-based customer query interface
- Optional lightweight public frontend for query access
4. Complete Documentation
- Workflow documentation for every n8n module
- Deployment and configuration instructions
- Data schema and architecture diagrams
- Administrator guide for updating FDDs, magazines, and website scraping rules
Tech Stack
- Tools used
- n8n – Orchestrator for all workflows (scraping, API calls, data processing, automation)
- AWS S3 – Central data lake for raw & processed files
- OpenAI API – Embeddings, semantic search, NLP-based analysis
- Pinecone – Vector database for embeddings
- YouTube Data API v3 – Metadata, transcripts, and monitoring
- RSS Feed Trigger (n8n) – Podcast ingestion
- Google Cloud Vision API – OCR for APRO magazine pages
- HTTP Request & HTML Extract (n8n) – Website, SEC, and product monitoring
- Email Node (n8n) – Automated daily reports
- Webhook Node (n8n) – External query interface
- PDF/Text Parsing Pipelines – For filings, transcripts, and FDD documents
- Skills used
- Workflow automation (n8n)
- API integration & data extraction
- Vector database architecture
- Prompt engineering
- Automation of web scraping at scale
- Document parsing and preprocessing
- Data quality validation and error handling
- Design of monitoring & alert systems
- Frontend/API integration for customer queries
- Databases used
- AWS S3 (Object Storage) – Main repository for documents, transcripts, OCR outputs, and historical datasets
- Pinecone / Weaviate (Vector – Embeddings, semantic search, retrieval-augmented analysis
- Web Cloud Servers used
- AWS
- Google Cloud Vision – OCR service for magazines
- OpenAI Cloud – NLP model computations
- YouTube Data API servers – Data pipeline integration
What are the technical Challenges Faced during Project Execution
- Inconsistent data formats across SEC filings, transcripts, magazines, and websites
- Rate limitations from APIs such as YouTube, SEC EDGAR, and RSS feeds
- Unstructured documents (PDFs, scans, images) requiring OCR and custom parsing
- Daily website scraping issues due to dynamic HTML, React-based pages, and bot detection
- Ensuring continuous monitoring without workflow failures in long-running n8n processes
- Handling large file sizes in historical data (20 years of filings, video transcripts, images)
- Embedding and vector storage costs when scaling thousands of documents
- Maintaining data consistency during daily updates and synchronizations
- Error recovery when API calls fail or websites change their HTML structure
- Building accurate change detection for promotions, pricing, and product availability
How the Technical Challenges were Solved
- Standardization pipelines were built in n8n to normalize all text into a unified schema (JSON + text chunks).
- Backoff + retry mechanisms handled API rate limits automatically.
- OCR + NLP preprocessing converted scanned magazines and PDFs into structured text reliably.
- HTML Extract + CSS selector fallback logic was implemented to adapt to changing website structures.
- Heartbeat checks + error alert nodes ensured workflows restart or notify admins when failure occurs.
- Chunking large files allowed embeddings to be processed efficiently and stored cost-effectively.
- Daily incremental ingestion avoided reprocessing the full dataset each day.
- Diff-based algorithms compared new vs. previous snapshots to detect only material changes.
- Auto-healing workflows re-ran failed tasks and logged issues for later review.
- Scalable S3 storage architecture prevented bottlenecks and ensured long-term retrieval efficiency.
Business Impact
The completed system transforms fragmented industry knowledge into a real-time, always-on intelligence engine for the RTO sector. Key impacts include:
- 90% reduction in manual research time for analysts and leadership teams
- 24/7 real-time monitoring of competitors, pricing, and industry changes
- Instant access to 20 years of financial, operational, and qualitative insights
- Faster decision-making driven by automated trend detection and AI-driven summaries
- Improved competitive intelligence via daily automated web and product scanning
- Centralized, searchable knowledge base accessible via simple API or UI
- Lower operational cost due to automation replacing manual scraping and document review
- Better forecasting & strategy planning through NLP-powered analysis across millions of data points
Project Snapshots
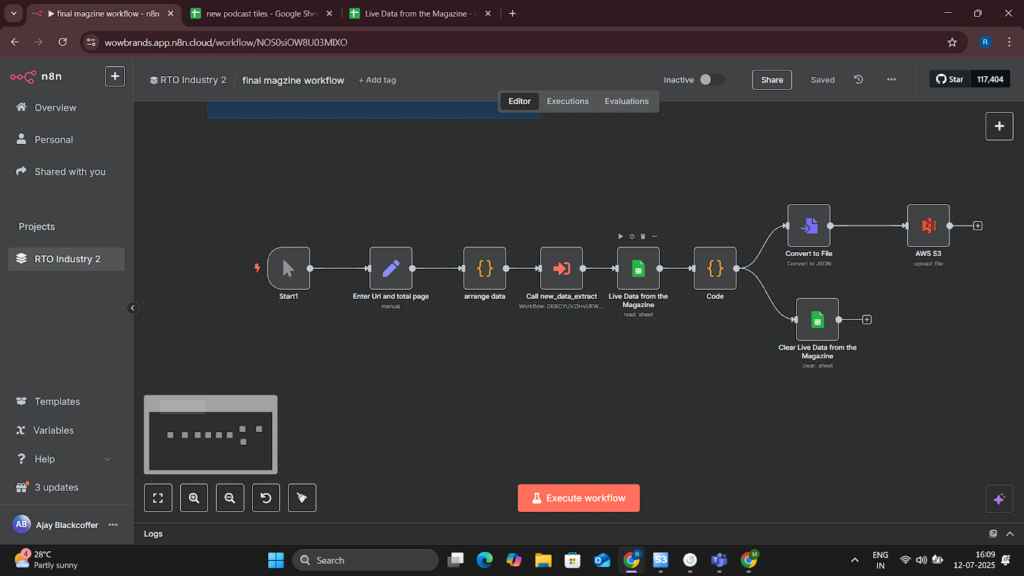
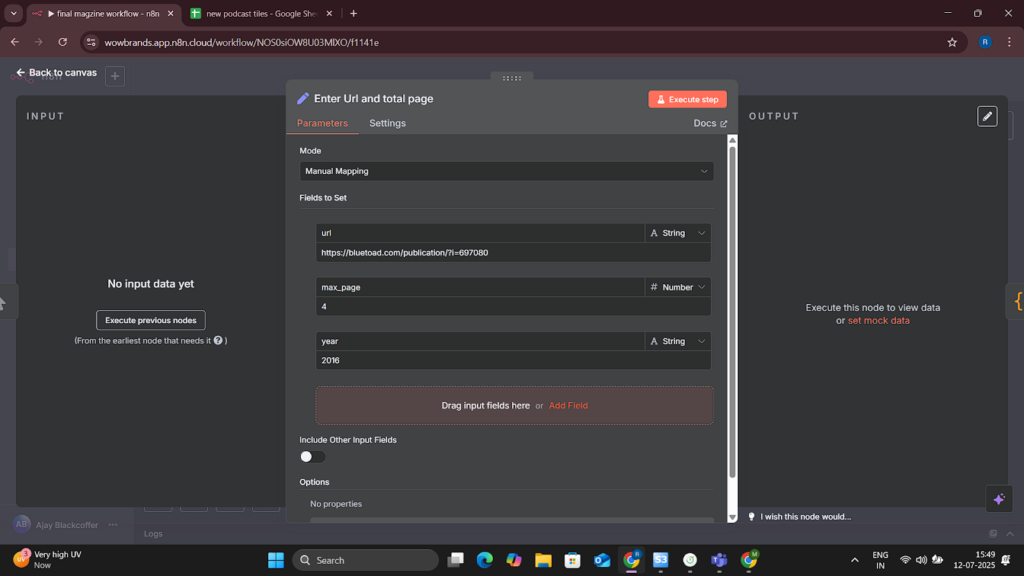
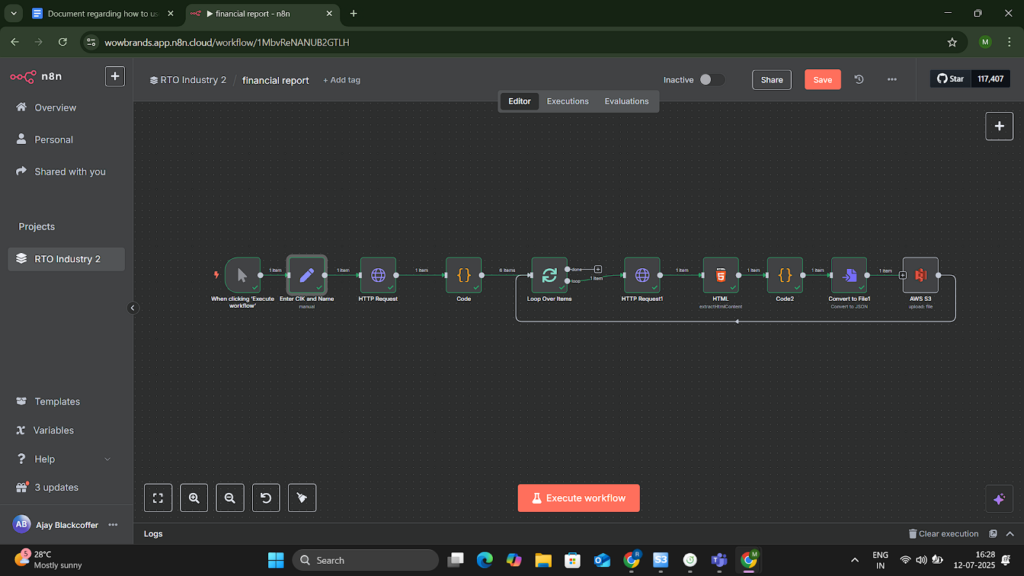
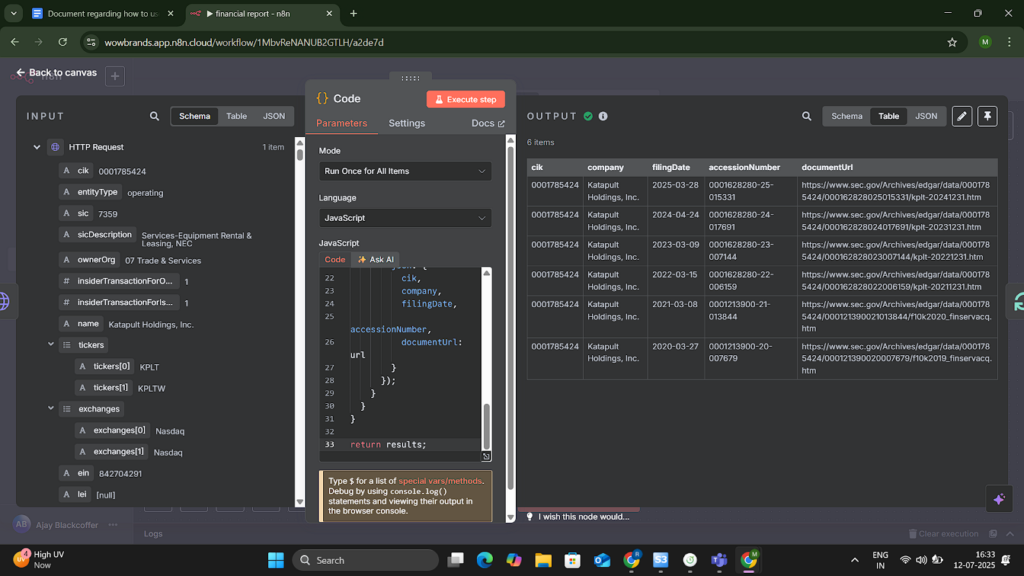
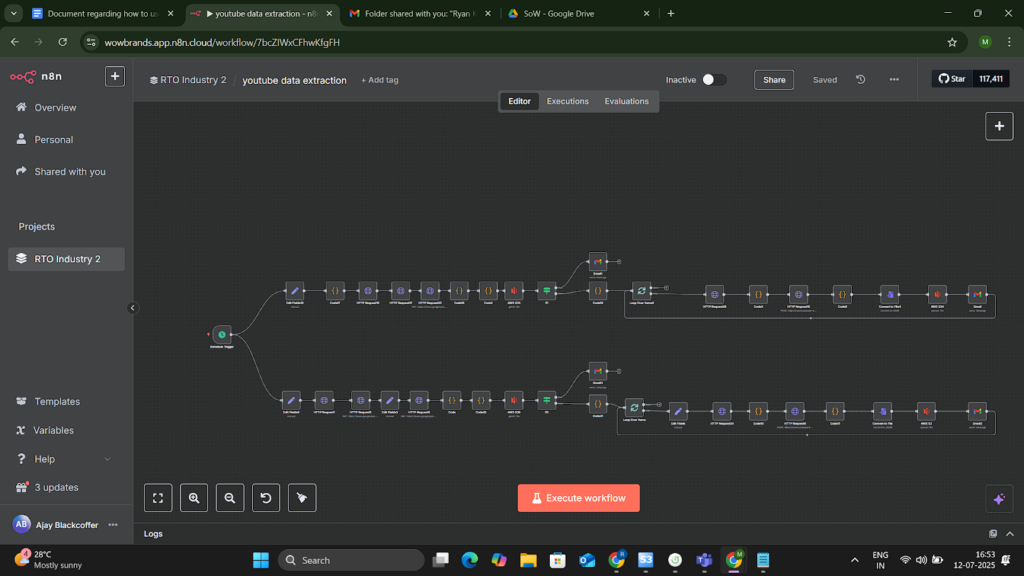
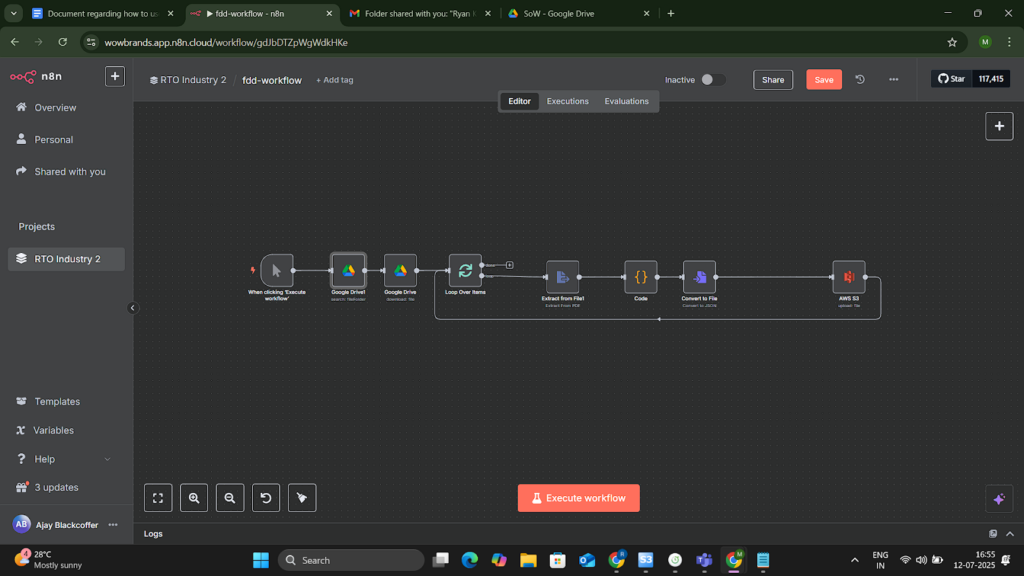
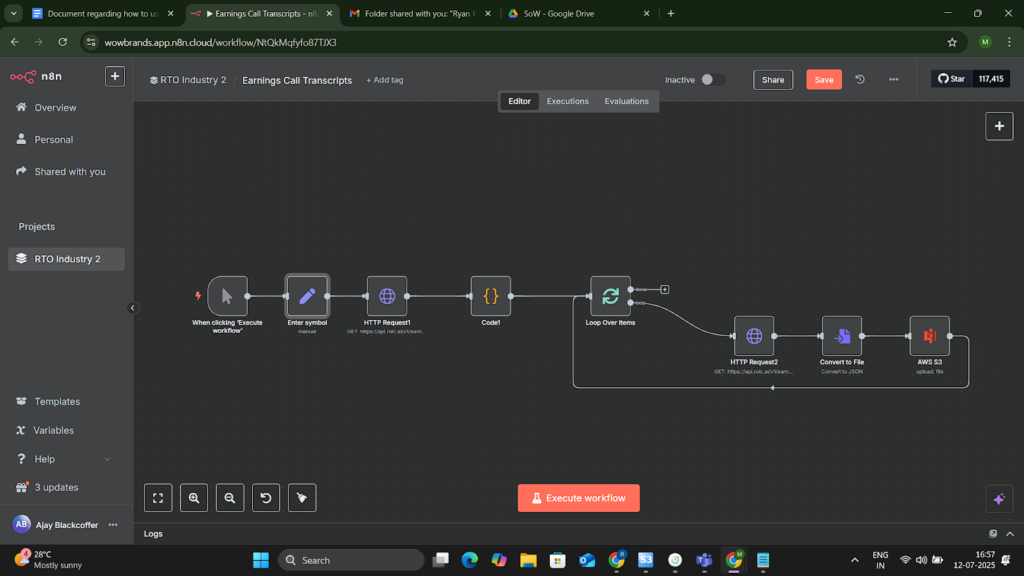
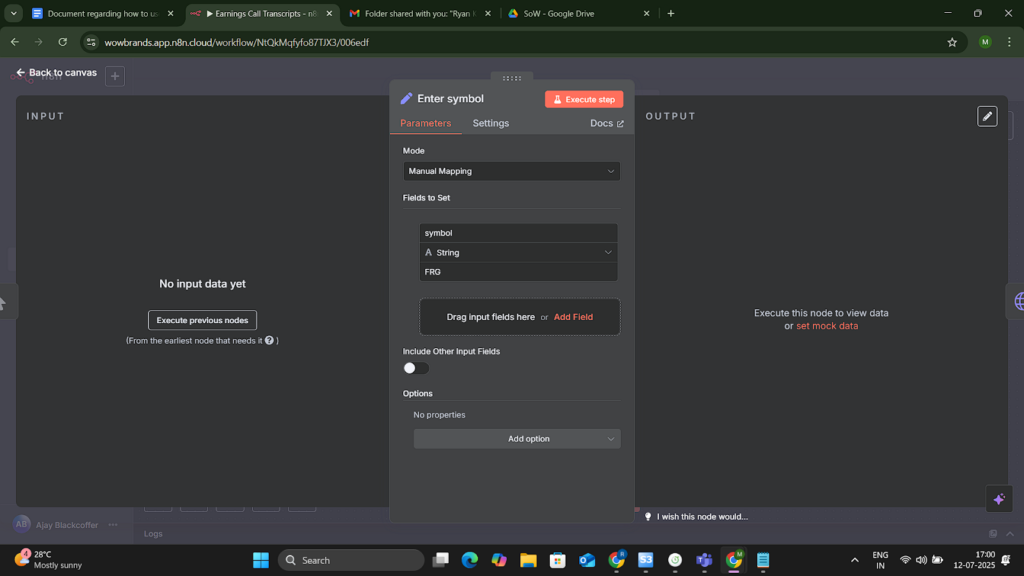
Project website url
https://wowbrands.app.n8n.cloud/projects/uE7MRe1Bqnfdb07D/workflows
Project Video
Contact Details
This solution was designed and developed by Blackcoffer Team
Here are my contact details:
Firm Name: Blackcoffer Pvt. Ltd.
Firm Website: www.blackcoffer.com
Firm Address: 4/2, E-Extension, Shaym Vihar Phase 1, New Delhi 110043
Email: ajay@blackcoffer.com
WhatsApp: +91 9717367468
Telegram: @asbidyarthy



















