


Introduction
In this document, we discuss the workflow of a Machine learning project this includes all the steps required to build the proper machine learning project from scratch.
This document will help you to understand how we go over data pre-processing, data cleaning, feature exploration, and feature engineering and show the impact that it has on Machine Learning Model Performance.
AI/ML workflow architecture
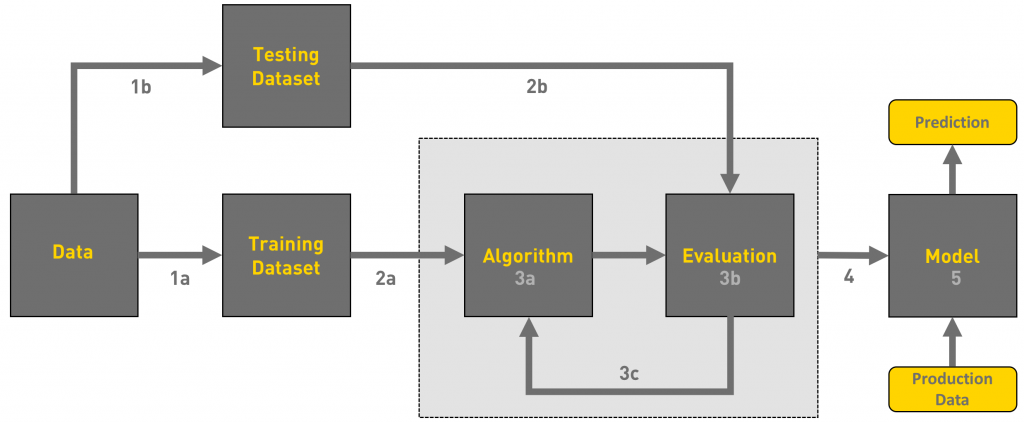
Understanding the machine learning workflow
We define the machine learning workflow in 5 stages.
- Gathering data
- Data pre-processing
- Researching the model that will be best for the type of data
- Training and testing the model
- Evaluation
What is the machine learning model?
The machine learning model is a piece of code; an engineer or data scientist makes it smart through training with data. So, if you give garbage to the model, you will get garbage in return, i.e. the trained model will provide false or wrong predictions.
1. Gathering Data
The process of gathering data depends on the type of project we desire to make, if we want to make an ML project that uses real-time data, then we can build an IoT system that using different sensors data. The data set can be collected from various sources such as a file, database, sensor, and many other such sources but the collected data cannot be used directly for performing the analysis process as there might be a lot of missing data, extremely large values, unorganized text data or noisy data. Therefore, to solve this problem Data Preparation is done.
2. Data pre-processing
Data pre-processing is one of the most important steps in machine learning. It is the most important step that helps in building machine learning models more accurately. In machine learning, there is an 80/20 rule. Every data scientist should spend 80% time for data pre-processing and 20% time to actually perform the analysis.
What is data pre-processing?
Data pre-processing is a process of cleaning the raw data i.e. the data is collected in the real world and is converted to a clean data set. In other words, whenever the data is gathered from different sources it is collected in a raw format and this data isn’t feasible for the analysis.
Therefore, certain steps are executed to convert the data into a small clean data set, this part of the process is called as data pre-processing.
Why do we need it?
As we know that data pre-processing is a process of cleaning the raw data into clean data, so that it can be used to train the model. So, we definitely need data pre-processing to achieve good results from the applied model in machine learning and deep learning projects.
Most of the real-world data is messy, some of these types of data are:
1. Missing data: Missing data can be found when it is not continuously created or due to technical issues in the application (IoT system).
2. Noisy data: This type of data is also called outliners, this can occur due to human errors (human manually gathering the data) or some technical problem of the device at the time of collection of data.
3. Inconsistent data: This type of data might be collected due to human errors (mistakes with the name or values) or duplication of data.
Three Types of Data
1. Numeric e.g. income, age
2. Categorical e.g. gender, nationality
3. Ordinal e.g. low/medium/high
How can data pre-processing be performed?
These are some of the basic pre-processing techniques that can be used to convert raw data.
1. Conversion of data: As we know that Machine Learning models can only handle numeric features, hence categorical and ordinal data must be somehow converted into numeric features.
2. Ignoring the missing values: Whenever we encounter missing data in the data set then we can remove the row or column of data depending on our needs. This method is known to be efficient but it shouldn’t be performed if there are a lot of missing values in the dataset.
3. Filling the missing values: Whenever we encounter missing data in the data set then we can fill the missing data manually, most commonly the mean, median or highest frequency value is used.
4. Machine learning: If we have some missing data then we can predict what data shall be present in the empty position by using the existing data.
5. Outliers detection: There are some error data that might be present in our data set that deviates drastically from other observations in a data set. [Example: human weight = 800 Kg; due to mistyping of extra 0]
3. Researching the model that will be best for the type of data
Our main goal is to train the best performing model possible, using the pre-processed data.
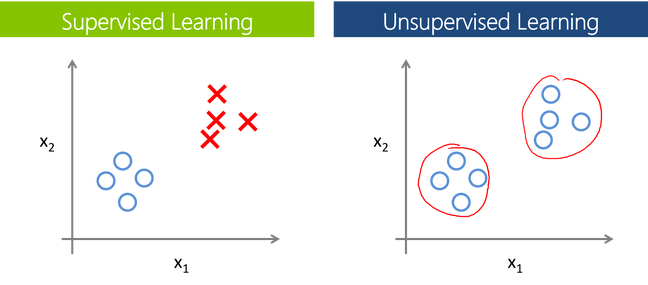
Supervised Learning:
In Supervised learning, an AI system is presented with data that is labeled, which means that each data tagged with the correct label.
The supervised learning is categorized into 2 other categories which are “Classification” and “Regression”.
Classification:
The classification problem is when the target variable is categorical (i.e. the output could be classified into classes — it belongs to either Class A or B or something else).
A classification problem is when the output variable is a category, such as “red” or “blue”, “disease” or “no disease” or “spam” or “not spam”.
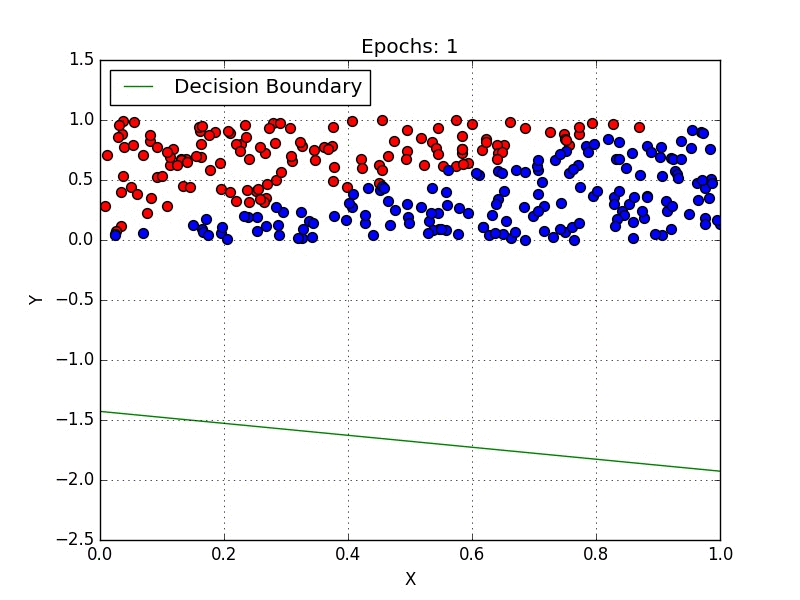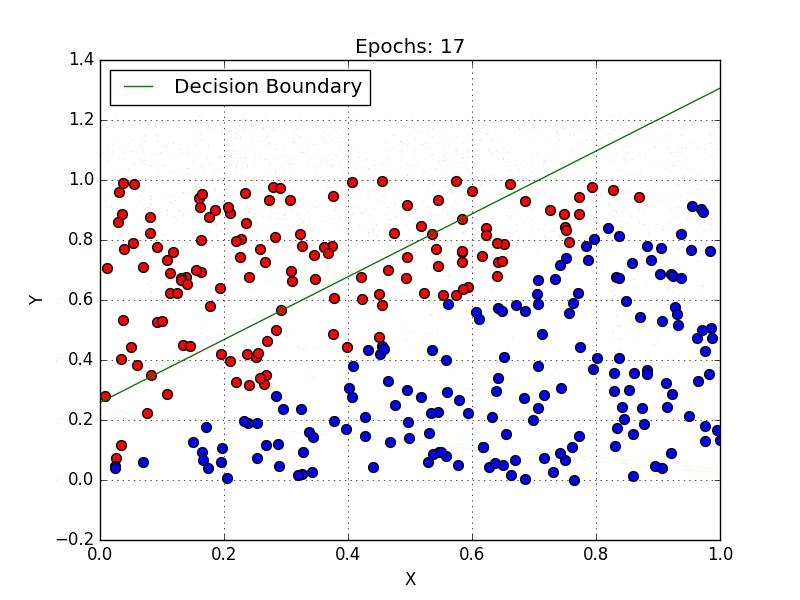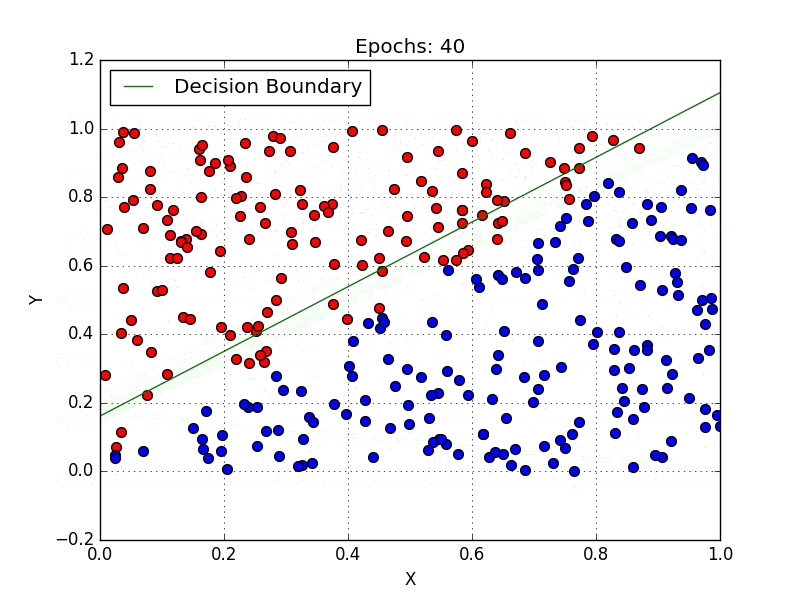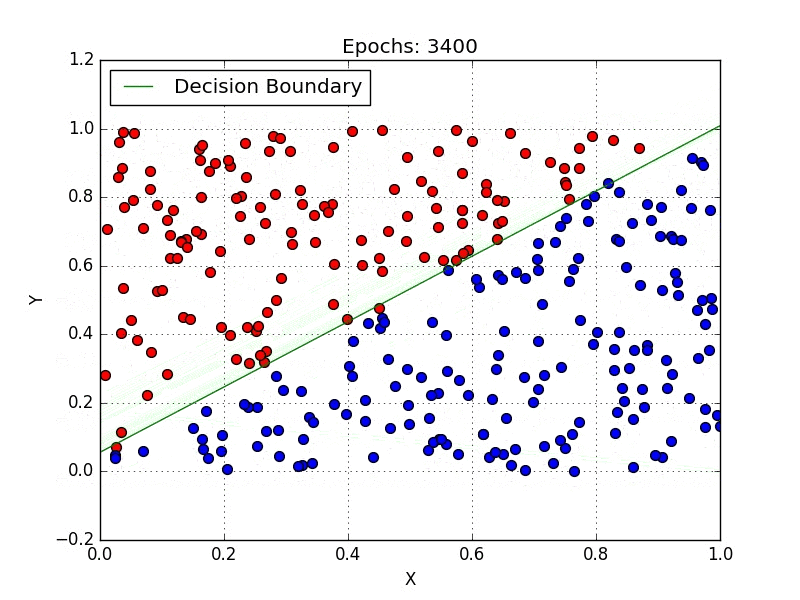
These some most used classification algorithms.
- K-Nearest Neighbor
- Naive Bayes
- Decision Trees/Random Forest
- Support Vector Machine
- Logistic Regression
Regression:
While a Regression problem is when the target variable is continuous (i.e. the output is numeric).
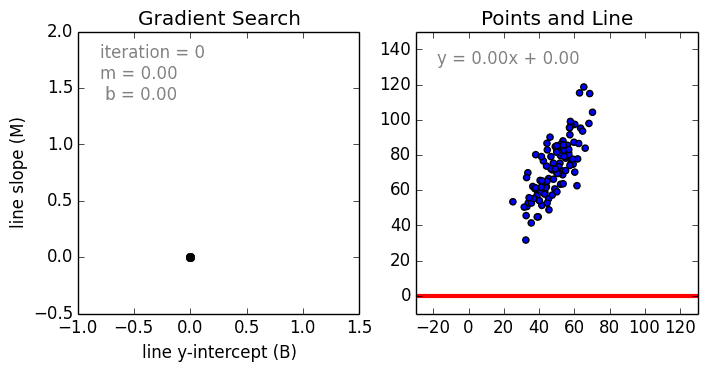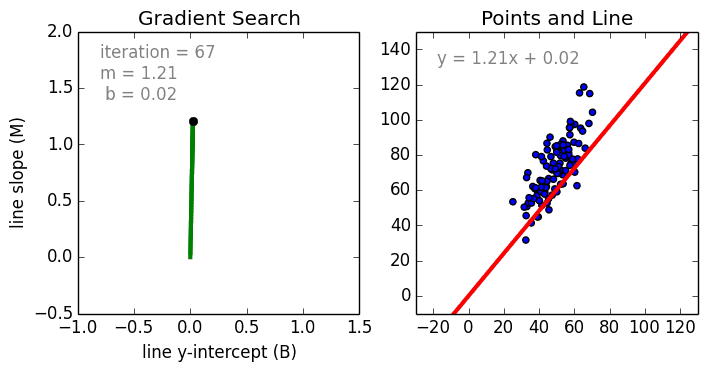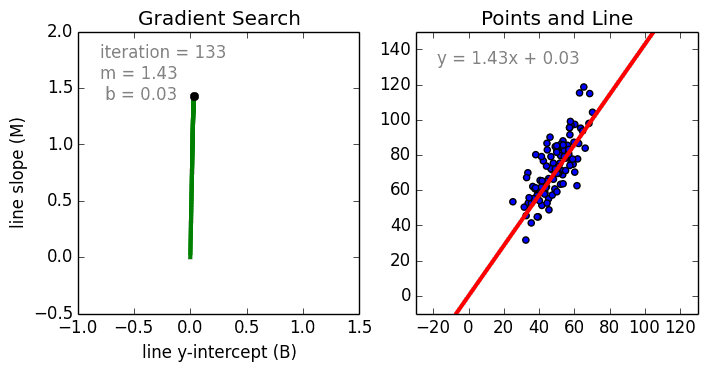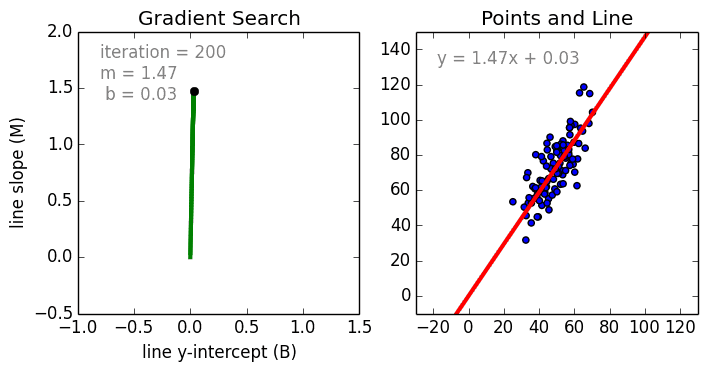
As shown in the above representation, we can imagine that the graph’s X-axis is the ‘Test scores’ and the Y-axis represents ‘IQ’. So we try to create the best fit line in the given graph so that we can use that line to predict any approximate IQ that isn’t present in the given data.
These some most used regression algorithms.
- Linear Regression
- Support Vector Regression
- Decision Tress/Random Forest
- Gaussian Progresses Regression
- Ensemble Methods
Unsupervised Learning:
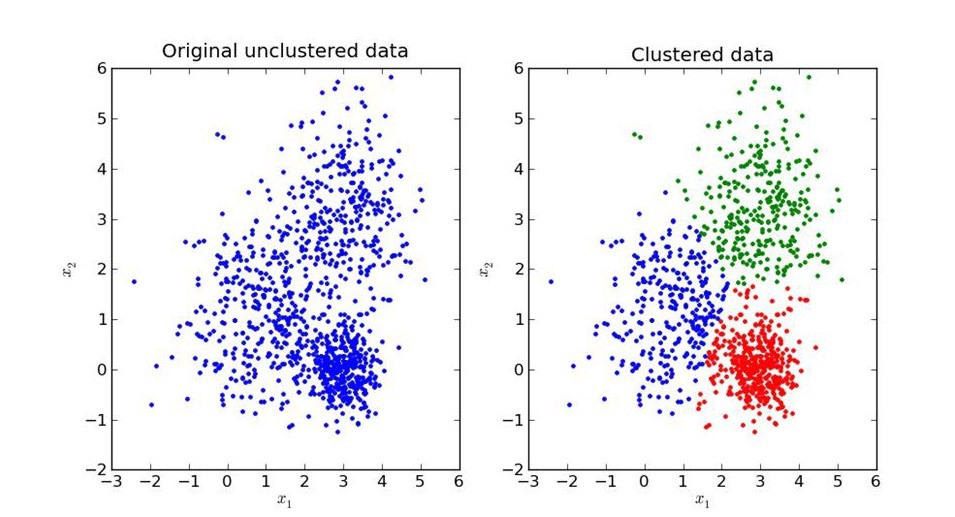
In unsupervised learning, an AI system is presented with unlabeled, un-categorized data and the system’s algorithms act on the data without prior training. The output is dependent upon the coded algorithms. Subjecting a system to unsupervised learning is one way of testing AI.
The unsupervised learning is categorized into 2 other categories which are “Clustering” and “Association”.
Clustering:
A set of inputs is to be divided into groups. Unlike in classification, the groups are not known beforehand, making this typically an unsupervised task.
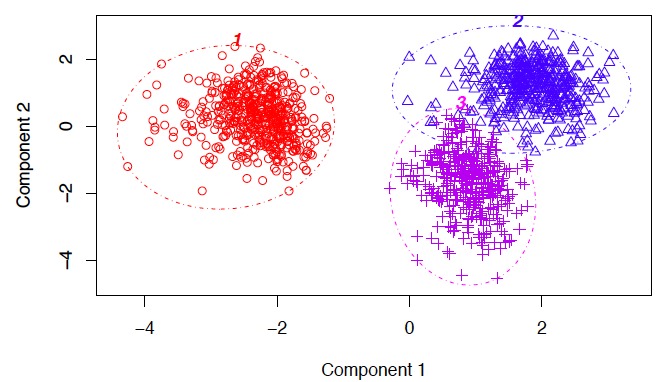
Methods used for clustering are:
- Gaussian mixtures
- K-Means Clustering
- Boosting
- Hierarchical Clustering
- K-Means Clustering
- Spectral Clustering
Overview of models under categories:
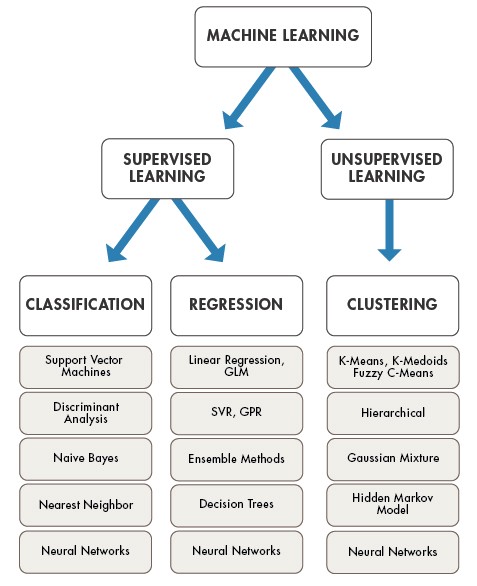
4. Training and testing the model on data
For training a model we initially split the model into 3 three sections which are ‘Training data’ ,‘Validation data’ and ‘Testing data’.
You train the classifier using ‘training data set’, tune the parameters using ‘validation set’ and then test the performance of your classifier on unseen ‘test data set’. An important point to note is that during training the classifier only the training and/or validation set is available. The test data set must not be used during training the classifier. The test set will only be available during testing the classifier.
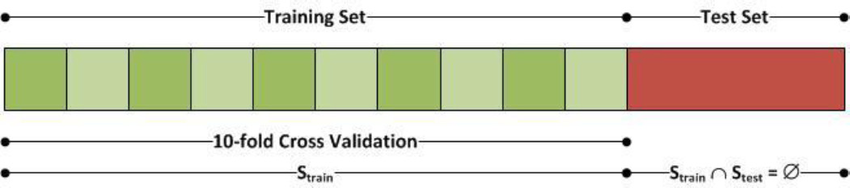
Training set: The training set is the material through which the computer learns how to process information. Machine learning uses algorithms to perform the training part. A set of data used for learning, that is to fit the parameters of the classifier.
Validation set: Cross-validation is primarily used in applied machine learning to estimate the skill of a machine learning model on unseen data. A set of unseen data is used from the training data to tune the parameters of a classifier.
Test set: A set of unseen data used only to assess the performance of a fully-specified classifier.
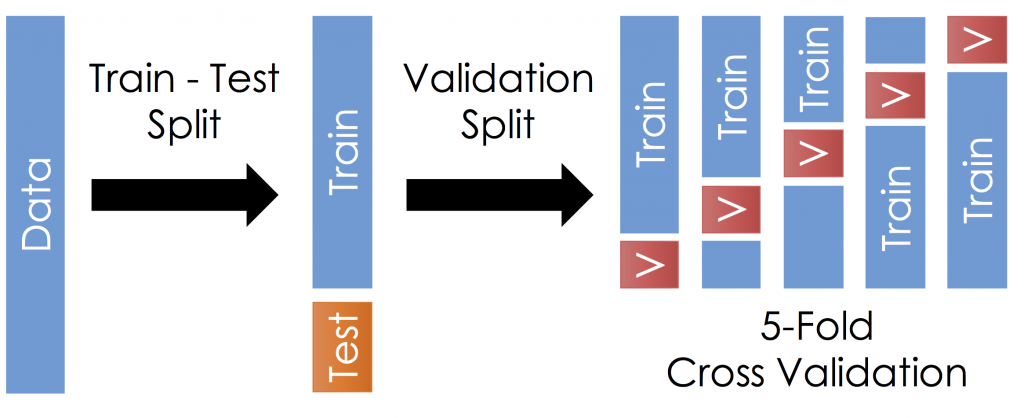
Once the data is divided into the 3 given segments we can start the training process.
In a data set, a training set is implemented to build up a model, while a test (or validation) set is to validate the model built. Data points in the training set are excluded from the test (validation) set. Usually, a data set is divided into a training set, a validation set (some people use ‘test set’ instead) in each iteration, or divided into a training set, a validation set and a test set in each iteration.
The model uses any one of the models that we had chosen in step 3/ point 3. Once the model is trained we can use the same trained model to predict using the testing data i.e. the unseen data. Once this is done we can develop a confusion matrix, this tells us how well our model is trained. A confusion matrix has 4 parameters, which are ‘True positives’, ‘True Negatives’, ‘False Positives’ and ‘False Negative’. We prefer that we get more values in the True negatives and true positives to get a more accurate model. The size of the Confusion matrix completely depends upon the number of classes.
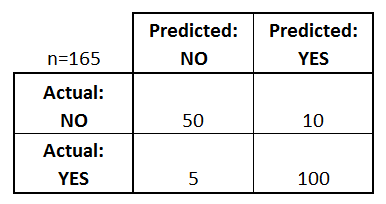
- True positives : These are cases in which we predicted TRUE and our predicted output is correct.
- True negatives : We predicted FALSE and our predicted output is correct.
- False positives : We predicted TRUE, but the actual predicted output is FALSE.
- False negatives : We predicted FALSE, but the actual predicted output is TRUE.
We can also find out the accuracy of the model using the confusion matrix.
Accuracy = (True Positives +True Negatives) / (Total number of classes)
i.e. for the above example:
Accuracy = (100 + 50) / 165 = 0.9090 (90.9% accuracy)
5. Evaluation
Model Evaluation is an integral part of the model development process. It helps to find the best model that represents our data and how well the chosen model will work in the future.

To improve the model we might tune the hyper-parameters of the model and try to improve the accuracy and also looking at the confusion matrix to try to increase the number of true positives and true negatives.









 Tools, categorized based on their functionality and capabilities")

