


Client Background
Client: A leading tech firm in the USA
Industry Type: IT
Services: SaaS, Products
Organization Size: 100+
The Problem
As per the guidelines and discussion. Political Research Automated Data Acquisition (PRADA) in the following phases which included.
1. Get pics for existing EOs (Elected Officials)
2. Get new EOs and Pictures.
3. Run QA checks regularly on EOs
4. Get data from government Facebook pages.
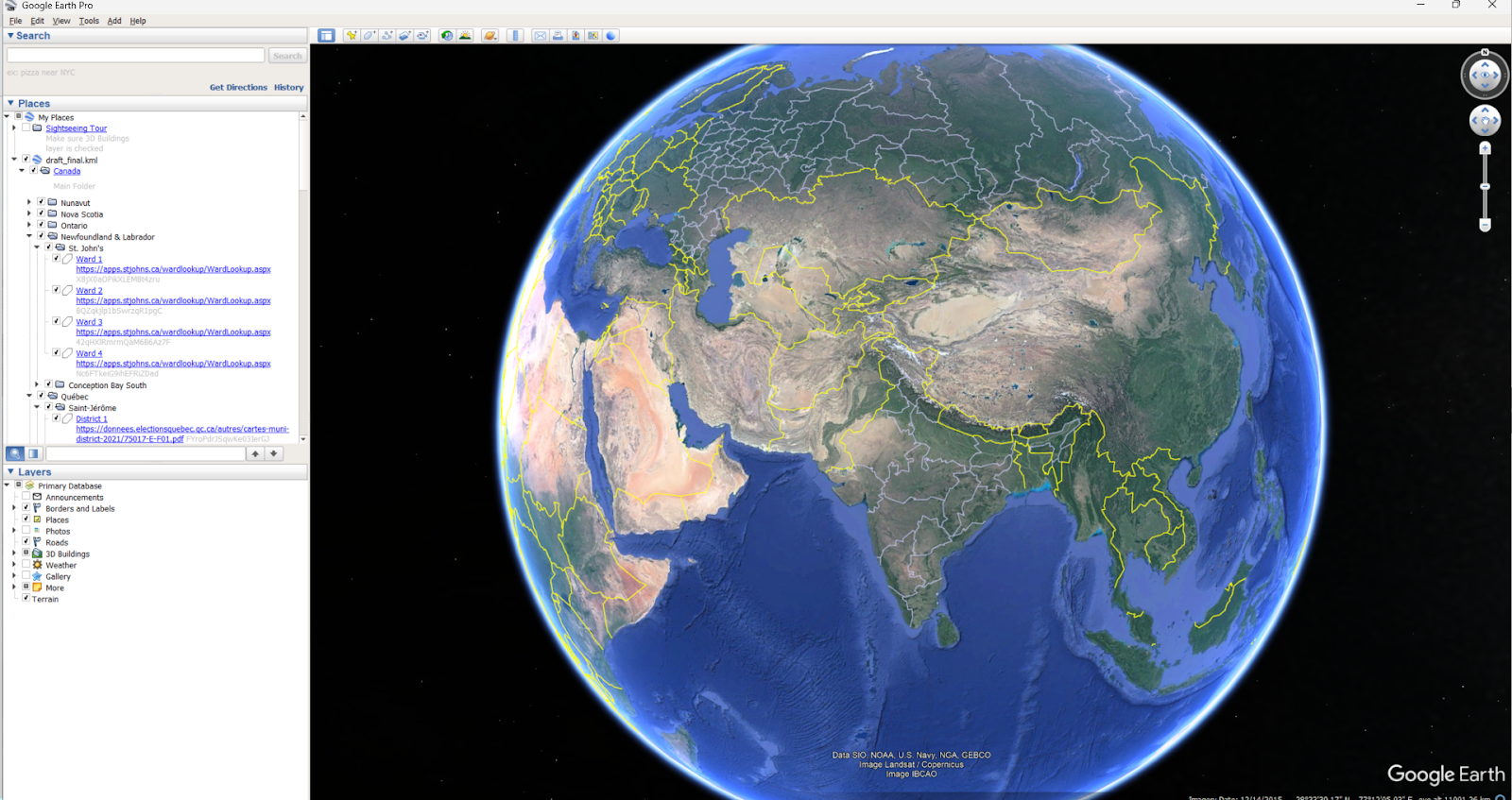
5. Geospatial project: Create a new version of provided KML without using google earth. Creating a nested directories which contained description and Map-URL at the designated location.
6. Get data of US States and Counties(Including Boroughs and Parishes)
By building an automated generated structured data that allows a non – programmer to create a config for each page allowing a bot to scrap and update the data.
Our Solution
We created an automated python scripts for designated phases with respective requirements. Solutions to various type of problems varied such as most of data scrapping automation was done through python developed scripts including the geospatial KML task. In addition to this different ranges of data was scrapped generated directed output for the respective tasks in the form of CSV format. So the user’s main aim requirement was achieved i.e. a non programmer could create a con-fig and initiate a bot to scrap the required data.
Solution Architecture
The majority task of project consisted of web data scraping automation so a high- level overview, and specific implementation details of project shall will be as follows:
- Web Scraping Framework: Python as a coding language was used in almost all of the tasks and the framework used for data scraping included Beautiful-Soup, Selenium and Web drivers. These libraries provide tools and functionalities to navigate web pages, extract data, and handle various HTML elements.
- Data Extraction and Parsing: Use the selected web scraping library to extract the desired data from the web pages provided either in the data sheet or within the websites of URLs given in the sheet. This involves locating HTML elements, applying filters or selectors, and parsing the extracted data.
- Data Processing: Followed by data extraction it was cleansed, transformed and aggregated to a structured form such as pandas’ Data Frame followed by a CSV file. In the case of geospatial task it resulted to generation of nested folders in a kml file.
- Data Storage: The how and where to store the scrapped data was determined which is local file system in the form of CSV (Comma Separated Values). As it was the appropriate data storage solution according to need of the project. In addition to this the geospatial task had the output in the form of kml file as polygons inside directories of nested folders.
Deliverables
| Tasks | Outputs (CSV/KML/XLSX) | Python Scripts | |
| Canada EOs | mydata.csv | Script1.py | Script2.py |
| Geospatial Task | Electoral Districts.kml | – | |
| Facebook Scrapping of EOs | EO_OUTPUT_O.csv | final_eo_scrapping.py | |
| Facebook Scrapping of 429 Cities | Output_DRAFT_429_CITIES.csv | Facebook_image_scrapping.py | |
| USA States Website URLs | ScreenScrapingt.csv | final_50_states_scrapping.py | |
| USA Counties Website URLs | US Website_final_write.xlsx | county_scrapping.py |
Tools used
- Python (Programming Language)
- Beautiful Soup
- Selenium
- Pandas
- Numpy
- Simplekml
- re (regular expressions)
Language/techniques used
- Python (Programming Language) – It is an interpreted language, which allows quick prototyping and interactive coding. Its versatility can be is one of the reasons for its major applications. Different libraries and tools were used in this project for various data solutions.
- Beautiful Soup – A python library used for web scraping and parsing HTML and XML documents. It provides a convenient way to extract from the said files. It eases out the work flow from parsing to data extraction and encoding handling as well.
- Selenium – A python library used for web browser automation like Chrome, Firefox, Safari and others. It interacts with elements such as clicking buttons, filling out forms and selecting drop down options. In this project we used it in Chrome. Selenium web driver was used for web automation. It acted as bridge between Python code and the Web browser.
- Pandas – It is Python’s versatile library that provides high performance data structure tools and it is built on top of Numpy. Data Frame is one of its key feature due to which this library was used. This key feature allows efficient manipulation, slicing, and filtering of structured data
- Numpy – It is also a python library aka Numerical Python as it is a fundamental library for scientific computing in Python.
- Simplekml – It is a python package which enables you to generate KML with as little effort as possible.
- re (Regular Expressions): It is a powerful tool in python sued for pattern matching and manipulations of strings.
Skills used
- Python Programming
- Web Fundamentals
- Web Scrapping using libraries such as BS, Selenium.
- Data Cleaning and Processing
- Problem- Solving and debugging.
- KML structure and handling using Python’s programming.
Databases used
None. All the structured data was in the form of either python Data Frames, CSV or Excel Sheets.
What are the technical Challenges Faced during Project Execution
- Firstly some of the web URLs were not accessible because they were restricted to particular range of IPs of that region
- Couldn’t fetch whole data through Beautiful Soup as it couldn’t parse whole tags.
- List of US Counties wasn’t provided in the given resource links
How the Technical Challenges were Solved
- Used VPN for accessing Official sites which were not generally accessible.
- Used Selenium Web driver to automate the direction at URLs which fetched complete html tags of the desired webpages.
- Performed a search and created structure data of list of counties of each state which was used as input to gain web URLs of counties of US.
Business Impact
- Enhanced Analysis: Web scraping allows businesses to gather valuable data from various websites. This information can provide insights to desired aim and objectives enabling businesses to make informed.
- Real-Time Monitoring and Upgradation: Web scraping can enable business to monitor changes or updates on website in real-time. This can be useful for tracking regulatory changes. It keeps the business and it’s data updated.
- Increased Efficiency: Automation eliminated the need for manual data collection, saving time and resources. With automated web scraping, business can extract large amount data quickly, accurately, improving overall operational efficiency.
Project Snapshots
Chrome driver initiated
Chrome driver visiting the directed links and accessing the image URLs

Directed to next link
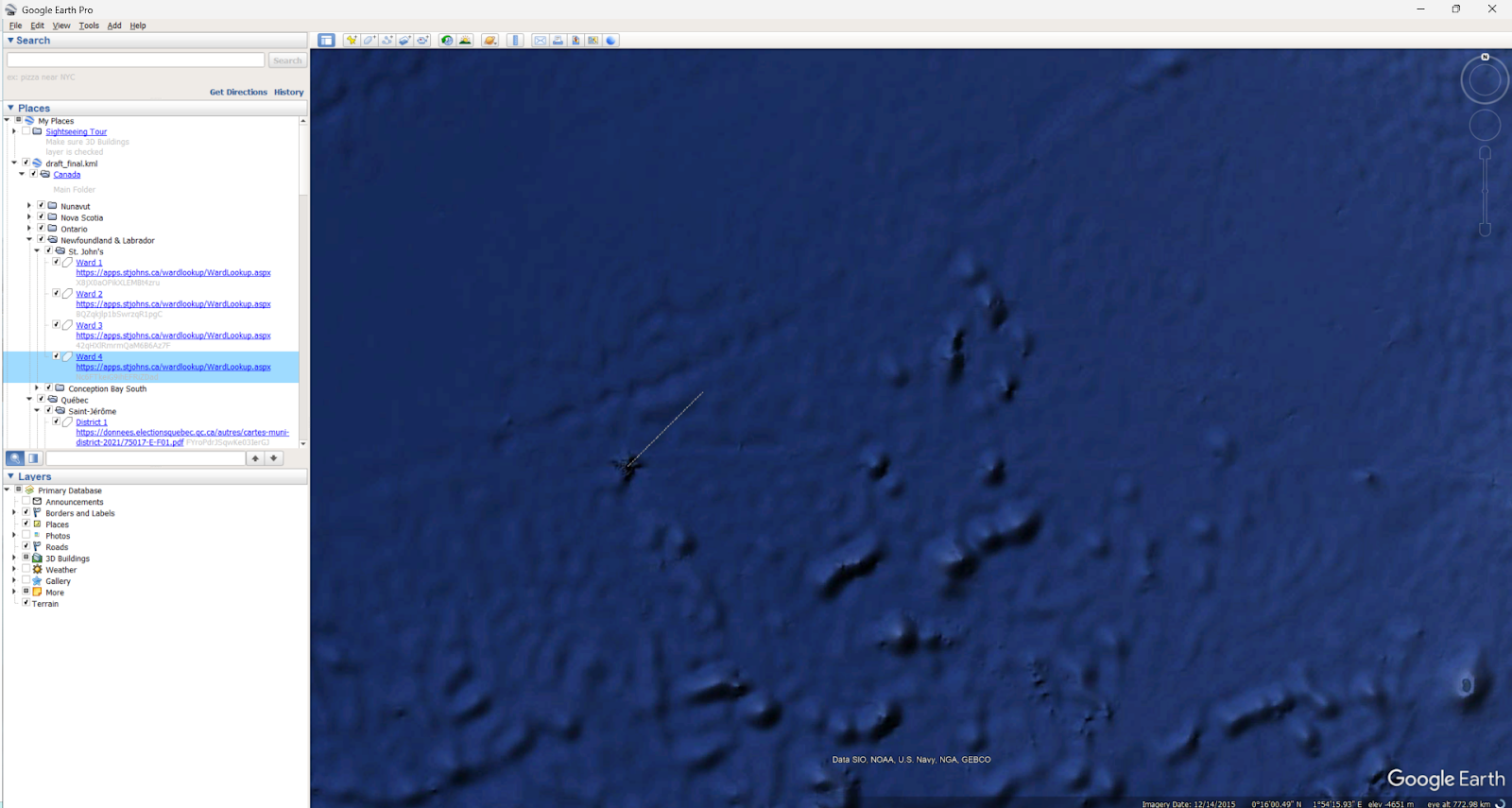
KML task

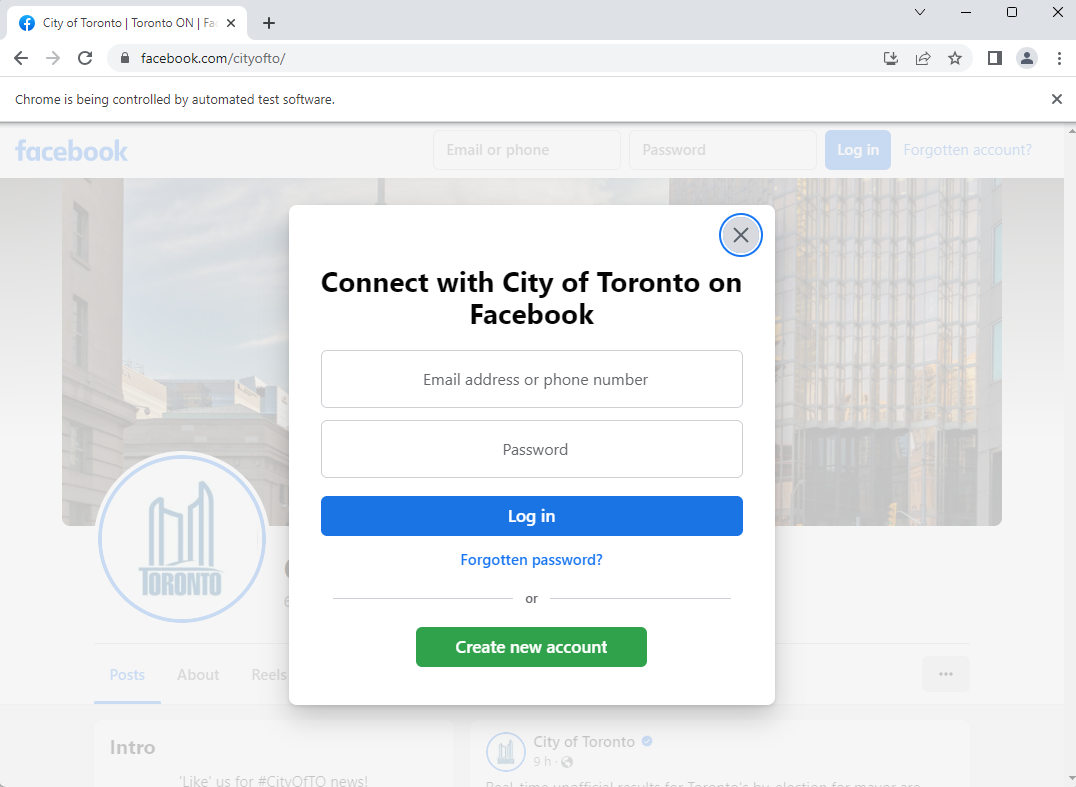
Facebook Data extraction
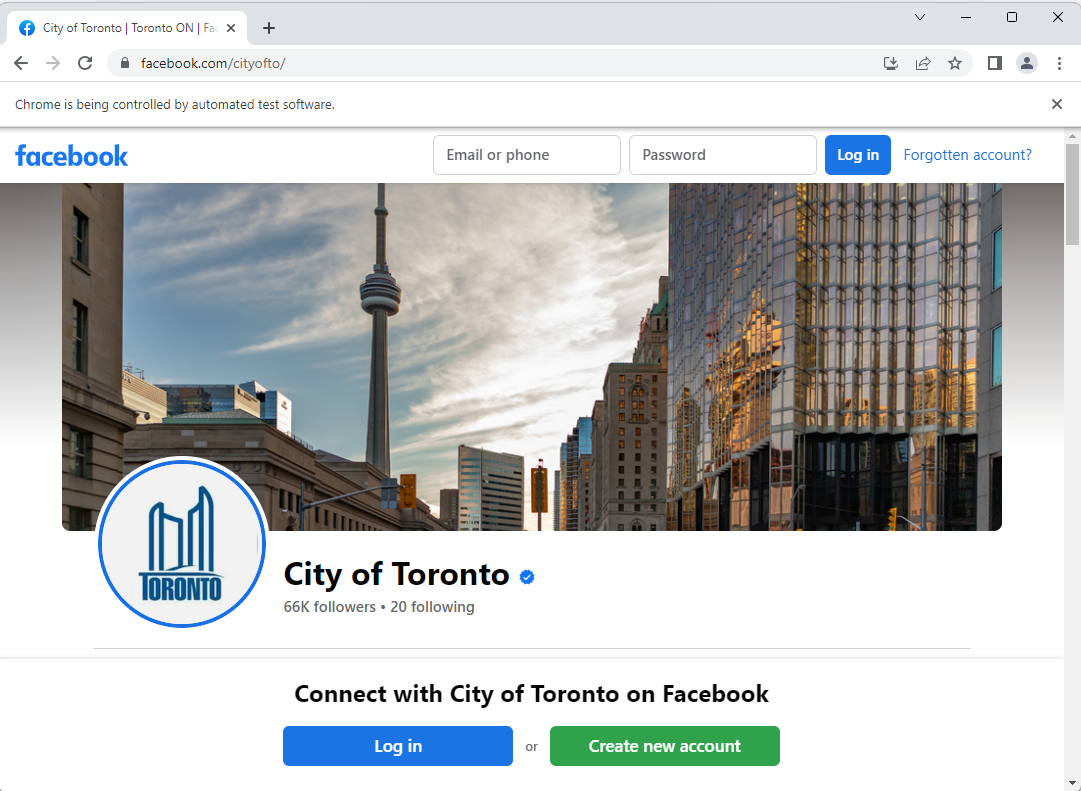
Data of State Governments of US


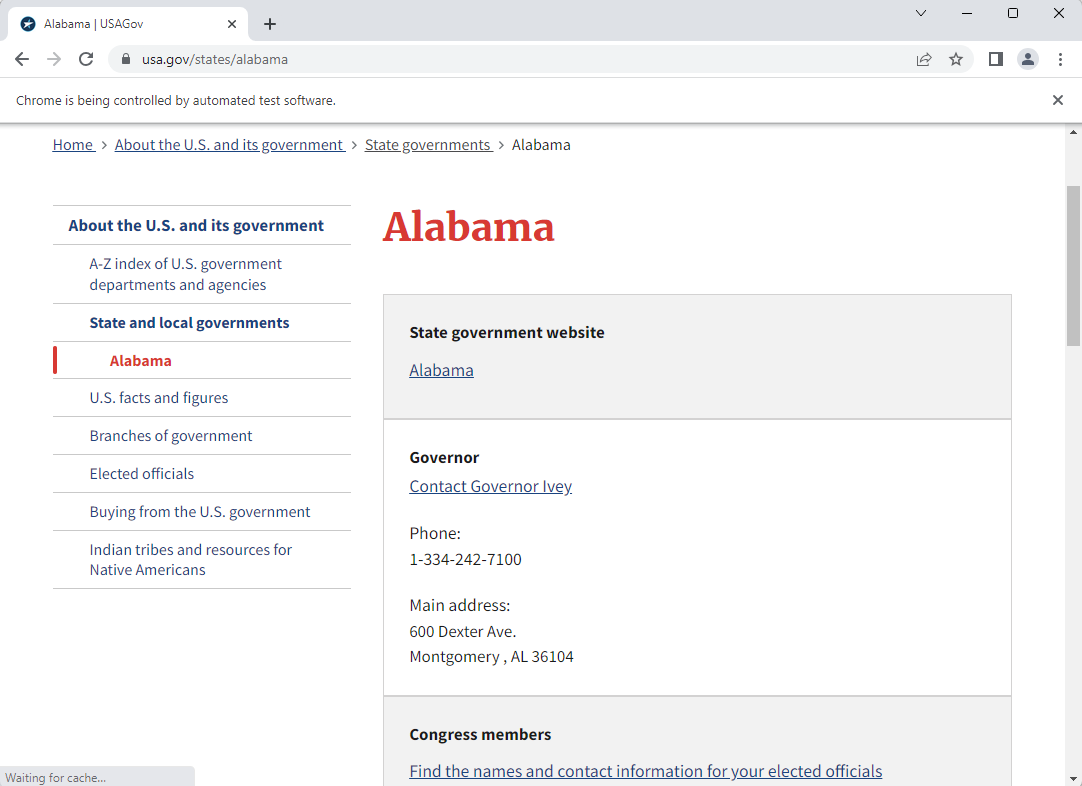

Accessing links through wiki directing to counties

Nesting within the list of counties of a particular state
Finding and Extracting link of the website of County

Project website url
The GitHub repository link:- https://github.com/AjayBidyarthy/Paul-Andr-Savoie/tree/main
Project Video
Contact Details
Here are my contact details:
Email: ajay@blackcoffer.com
Skype: asbidyarthy
WhatsApp: +91 9717367468
Telegram: @asbidyarthy
For project discussions and daily updates, would you like to use Slack, Skype, Telegram, or Whatsapp? Please recommend, what would work best for you.



















