


Client Background
- Client: A leading travel firm in Singapore
- Industry Type: Travel and Transportation
- Products & Services: Cab services
- Organization Size: 2000+
Our Solution
We developed an automated, serverless solution to parse toll statement PDFs from multiple sources (Linkt and NSW Government), extract relevant trip and billing data, and cross-reference with Drive Mate trip records to identify applicable trips. The solution dynamically computes trip mappings and updates them as new listings are added.
Solution Architecture
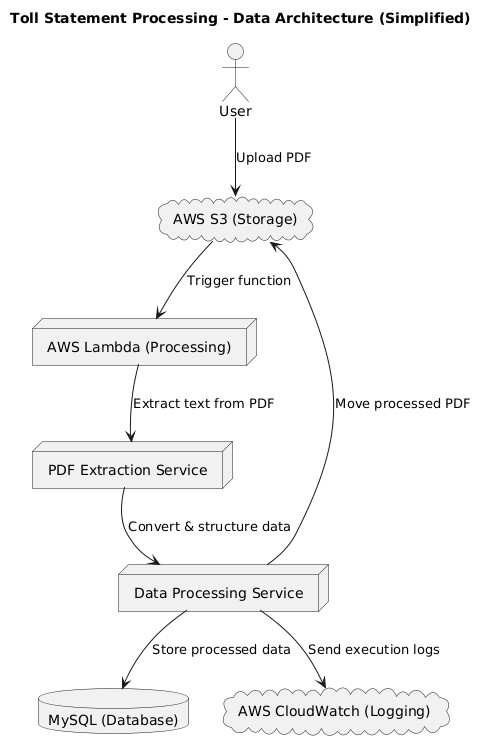
Deliverables
- PDF parsing service deployed using AWS Lambda
- Integrated pipeline to match toll entries with trip and listing data
- Storage of parsed and enriched data into a centralized database table
- Trigger-based re-evaluation mechanism for unmatched entries
- Dockerized script deployed through AWS ECR
Tools Used
- AWS Lambda
- AWS S3
- AWS ECR
- Docker
- PostgreSQL
- PDFPlumber / PyMuPDF (for PDF parsing)
- MySQL
Language/Techniques Used
- Python (PDF parsing, logic handling, database interaction)
- SQL (trip and listing joins)
- Docker for environment packaging
- Event-driven programming with S3 Triggers
Model Used
Not ML-based; logic-driven model for data parsing and time-based trip matching using structured joins.
Skills Used
- Python scripting
- Dockerization
- Event-driven cloud architecture
- ETL pipeline development
- Data modeling and SQL optimization
Databases Used
- PostgreSQL (sync_db_au_prod, table: host_toll_statements)
Web Cloud Servers Used
- AWS Lambda
- AWS S3
- AWS ECR
- AWS CloudWatch (for logs and monitoring)
Technical Challenges Faced During Project Execution
- Handling different formats of toll statements (Linkt vs NSW Gov)
- Parsing unstructured text from PDFs reliably
- Matching toll data to Drive Mate trips without a direct unique identifier
- Ensuring idempotency and atomicity in trip matching logic
- Delayed matching due to missing tag_number in initial uploads
How the Technical Challenges Were Solved
- Used custom parsers tailored for each company’s statement format
- Implemented robust regex and text extraction techniques
- Cross-referenced tag numbers with publicData.deviceManagement.tolltag.tagNumber and matched with trip data using timestamp logic
- Created fallback triggers to reprocess unmatched entries when new listing data is added
- Deployed through Docker and Lambda for auto-scaling and event-driven execution
Business Impact
- 100% automation of toll parsing and trip identification
- Reduced manual intervention and data entry time by over 90%
- Enabled real-time integration of toll data into Drive Lah’s backend systems
- Improved trip billing accuracy and transparency for users
- Streamlined operations and enhanced the customer experience



 Tool using BERT")



")



