


Client Background
Client: A leading business school worldwide
Industry Type: R&D
Services: R&D, Innovation
Organization Size: 100+
Project Objective
Objective of this project is to research and collect news article data sourcing from Canada, based on the keyword.
Project Description
There were 3 phases of the project.
- Phase 1– Data collection and selection
- Data related to anyone coming to Canada (new comers)
- Data related to anyone coming to Canada (new comers)
- Canadian policy to new comers
- i.e. from any country to Canada
- Data containing News, press, think tanks, government policy documents, or research institutions releasing the news or press about
- The news source should be limited to Canada only
- Time span- 2005 to 2021
- Output- Excel having URLs or the documents along with the source type, keywords, and date on which that article is posted.
- Phase 2– Documents text data extraction
- Develop tool to collect and extract data from each URL.
- Clean and save the texts in the text documents
- Phase 3– Textual Analysis
- Sentiment Analysis
- Analysis of readability
- Topic modelling
Our Solution
We provide them with completed Phase 1 in an excel sheet and ongoing samples for Phase 2. Also work for Phase 3 has been started in between to complete the Project as soon as possible in a best way.
Project Deliverables
There is a file containing excel sheet and a word file containing a summary of the dataset and folders of text files containing samples of data from Phase 2.
Tools used
Python, PyCharm, Jupyter Notebook, Microsoft Excel, Google Chrome is used to complete different phases of this project
Language/techniques used
Python programming language is used to do Web Scraping, Automation, Data Engineering in this project.
Models used
SDLC is a process followed for a software project, within a software organization. It consists of a detailed plan describing how to develop, maintain, replace and alter or enhance specific software. The life cycle defines a methodology for improving the quality of software and the overall development process.
We are using Iterative Waterfall SDLC Model as we have to follow our development of software in phases and we also need feedback on every step of the development of our project so as to keep track of the occurring changes with every step.
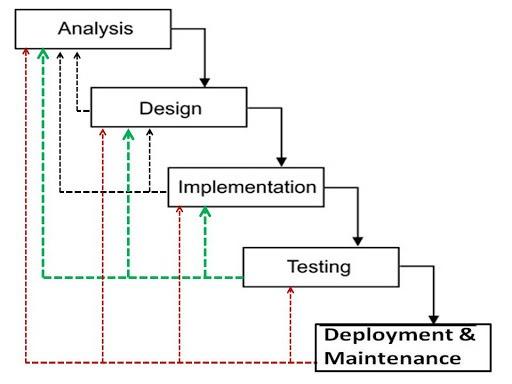
Figure 1 SDLC Iterative Waterfall Model
Skills used
Data scraping, cleaning, pre-processing and creating data pipelines are used in this project.
Databases used
We used the traditional way of storing the data i.e file systems.
What are the technical Challenges Faced during Project Execution
There were a lot of challenges we faced during the project execution.
- As on the internet, raw data is available to us. So, to search for the important data specifically related to Canada only, with a lot of keywords was a challenging part for us.
- Then, if we somehow manage to do the task by automating it upto some extent only, we are required to find the dates of the articles, news, think tanks, documents etc, that was also a challenging part.
- While working on Phase 2, we need to scrape the data from the URLs, so sometimes, the news articles were removed from the website, which we earlier took in our datasets which cause problems in extracting the data.
- Then cleaning the webpages was also challenge for us, because this project is for research, so data is important to us. So, it was difficult to take only that data from website which we require and are most important.
How the Technical Challenges were Solved
Below are the points used to solve the above technical challenges-
- We used sitemaps of websites to find different articles that we require according to the keywords, manual research was done to find out which URL will solve the purpose. Manual checking of results of automation tools, that we created, was done.
- To find the dates of the articles, we wrote multiple regular expressions, that will find the match for the dates that we need, also manual checking was done after that.
- To scrape removed webpages, we used WayBack machine or google archives, which stores all the deleted webpages.
- To clean the data, we filtered out various HTML tags, classes, ids by using regex, manual research.
Project Snapshots















")









