


Client Background
- Client Name: A leading R&D institution in the Europe
- Industry Type: Research / Data Analytics
- Products & Services: Communication network analysis, behavioral data insights
- Organization Size: 100+
About Client: The client works with large-scale communication datasets to analyze interaction patterns between individuals. Their objective was to convert raw email data into a structured, analyzable format with accurate user-level mapping.
The Problem
The client had multiple Excel datasets containing email communication logs, but:
- No direct mapping between email addresses and user IDs
- Multiple formats of email data (plain emails, “Name <email>”)
- Large data volume (multiple files, high row count)
- No structured output for analysis
- Missing and inconsistent data (encoding issues, unmapped users)
- No validation mechanism to ensure correctness
This made it difficult to:
- Analyze communication patterns
- Track user interactions
- Ensure data reliability
Our Solution
This project was built in a multi-phase data processing pipeline as per the customer requirements that evolved into a scalable and validated system.
Phase-wise Evolution:
- Phase 1–2: Basic mapping of sender and recipients to IDs
- Phase 3–4: Introduced chunk processing and multi-file handling
- Phase 5: Full pipeline with enrichment, validation, and reporting
Final Solution Capabilities:
- Maps sender and recipient emails to unique user IDs
- Handles multiple input formats (email + display name)
- Processes large datasets efficiently using chunking
- Generates structured output with dynamic columns
- Extracts temporal insights (month, day, weekday)
- Produces validation and quality reports
- Identifies unmapped users and zero-activity accounts
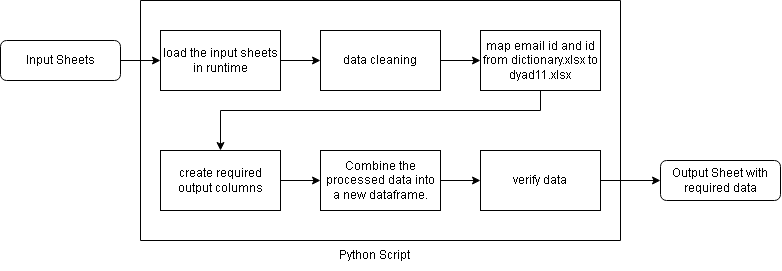
Solution Architecture
The solution follows a pipeline-based architecture:
- Input Layer
- Roster file (ID ↔ Email/Name mapping)
- Multiple message datasets (Excel files)
- Processing Layer
- Email extraction using regex
- Case-insensitive mapping
- Chunk-based file processing for scalability
- Dynamic column generation for recipients
- Enrichment Layer
- Time extraction (month, day, weekday)
- Message count per user
- Identification of inactive users
- Validation Layer
- Row count verification
- Mapping accuracy validation
- Zero-message verification
- Unmapped data analysis
- Output Layer
- Enriched Excel files
- Validation reports
- Updated roster with analytics
Deliverables
- Multiple enriched Excel datasets with ID mappings
- Updated roster file with message counts
- Validation reports:
- Mapping validation report
- Unmapped users report
- Zero-message verification report
- Clean and structured output ready for analysis
- Complete project documentation
- Execution-ready scripts
Tech Stack
- Language/techniques used
- Python
- Data Processing (ETL pipeline)
- Regex-based parsing
- Chunk-based processing for scalability
- Skills used
- Data Engineering
- Data Cleaning & Transformation
- Pipeline Design
- Validation & Quality Assurance
- Problem Solving for real-world messy data
What are the technical Challenges Faced during Project Execution
- Handling multiple email formats (plain + display name format)
- Managing large datasets efficiently without memory issues
- Ensuring accurate mapping despite inconsistent data
- Handling missing and unmapped users
- Dealing with UTF-8 encoding issues in input data
- Maintaining data integrity without modifying source files
- Creating dynamic output structure for varying recipients
- Validating data across multiple files consistently
How the Technical Challenges were Solved
- Used regex-based extraction for flexible email parsing
- Implemented chunk-based processing to handle large files
- Designed case-insensitive mapping logic for robustness
- Built fallback handling for display names when emails missing
- Created unmapped reporting system instead of forcing incorrect mapping
- Preserved input data and handled encoding issues without altering source
- Designed dynamic column generation based on recipient count
- Added multiple validation layers to ensure accuracy
Business Impact
- Enabled structured communication analysis
- Improved data accuracy and reliability
- Reduced manual data cleaning effort significantly
- Identified:
- Inactive users
- Missing roster entries
- Data inconsistencies
- Created a scalable system reusable for future datasets
- Delivered analysis-ready datasets for downstream insights
Project Snapshots
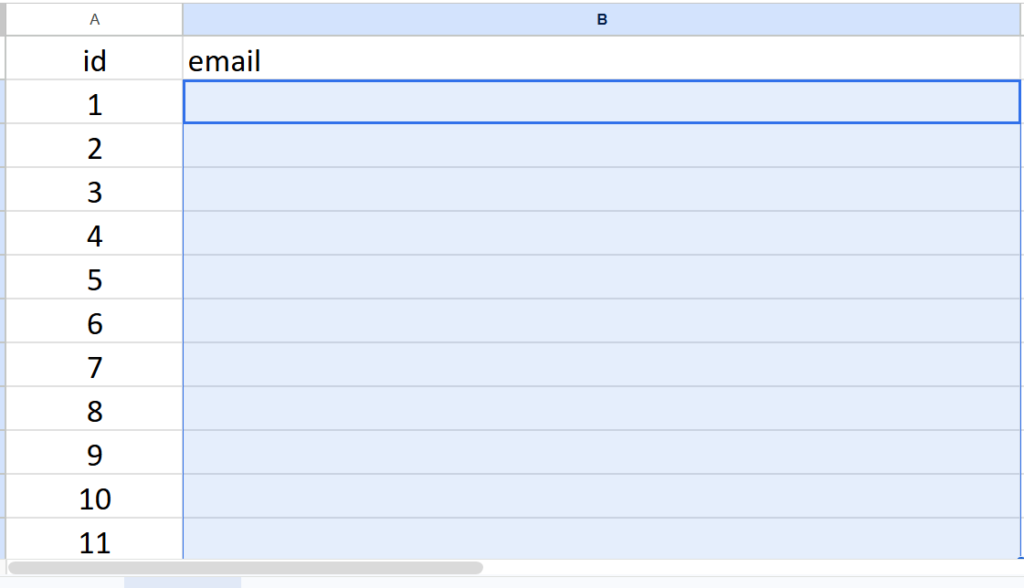
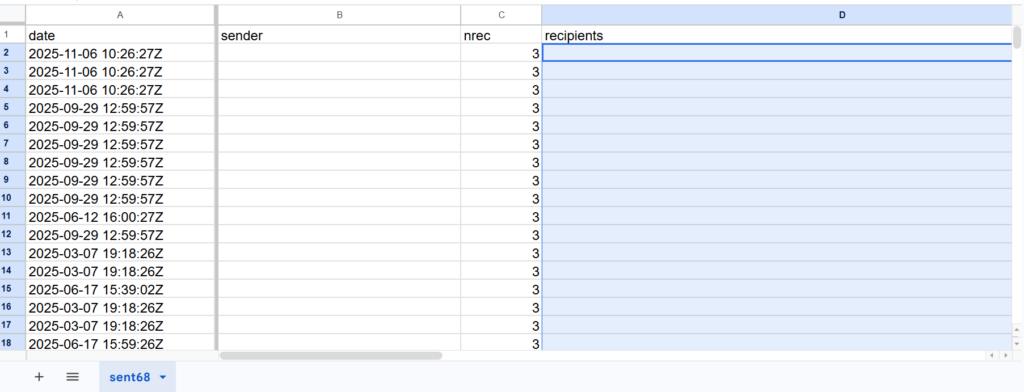
The Email ID (sender and receiver have been retracted for confidentiality)
1- Input Rooster and Data File:
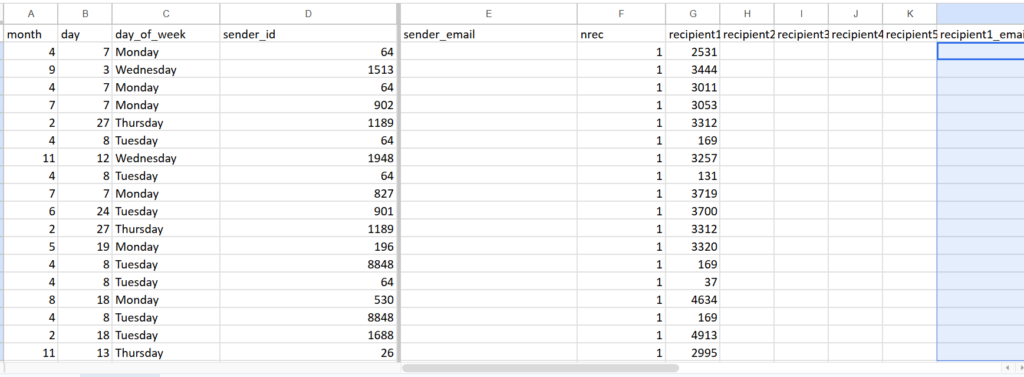
2- Updated Output file:
3- Updated Rooster output file:

")

















