


Client Background
Client: Valued Stats
Industry Type: Sports Analytics and Insights
Products & Services: Provides Statistical Analysis and Insights on Sports. Data-driven betting tools, prediction dashboards, and advisory insights.
Organization Size: 100+
The Problem
- Bettors require reliable, data-driven insights to maximize betting accuracy. Manual analysis of historical player performance, team consistency, and predictive accuracy is time-consuming and error-prone. An intelligent, automated system is needed to streamline this process, ensuring high accuracy (>90%) in betting recommendations.
Our Solution
We built an LLM-powered MLB Betting Assistant that:
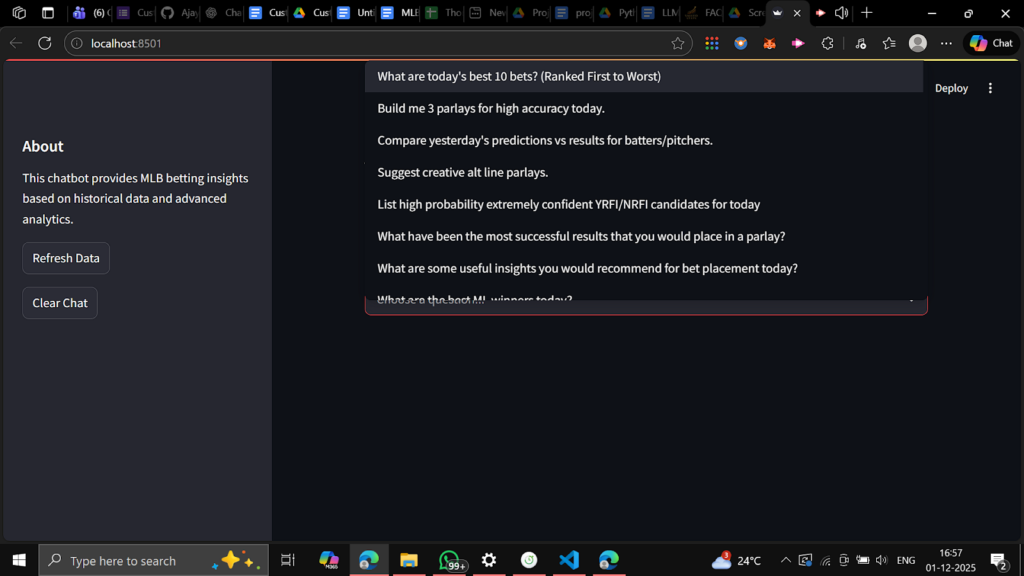
- Runs as a Streamlit web app with JWT-based access
- Only allows the user to choose from fixed dropdown questions (no freeform text as per requirements)
- Pulls the last 5 valid game days of data from an AWS RDS MySQL database
- Merges actual vs predicted historical stats for batting, pitching, innings, and game outcomes
- Calculates granular accuracy labels per player, prop, inning, and game total
- Feeds a curated data bundle + accuracy reports into an OpenAI Assistant (GPT)
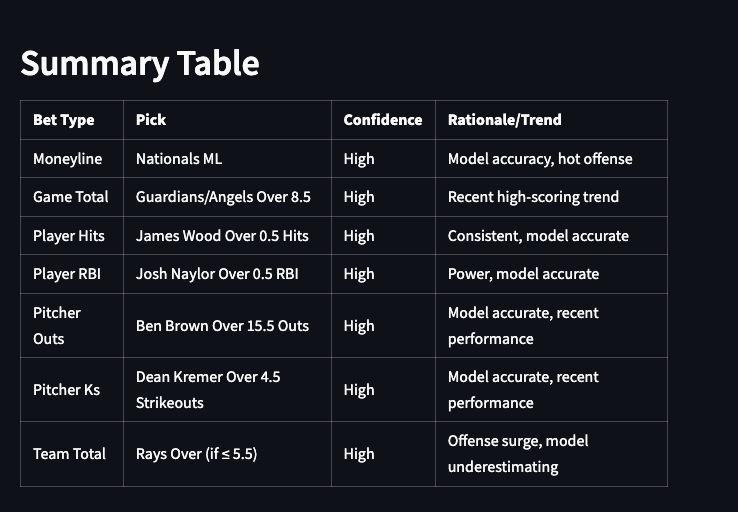
- Returns responses like “Top 10 bets,” “3 parlays,” “Top HR candidates,” etc., strictly grounded in that data with accuracy.
This design outputs:
- A clean UI for their predefined questions
- Transparent, data-backed outputs
- A pipeline that can be tuned, audited, and extended by their analytics team
Solution Architecture
The architecture comprises modular components with a structured flow:
User (Dropdown Selection)
↓
Streamlit Interface
↓
LLM Integration (GPT API)
↓
Backend Prediction & Accuracy Evaluator
↓
Historical Data (AWS RDS MySQL)
↓
Insight Engine & Recommendation Module
↓
Formatted Results (Betting Insights)
↓
Displayed via Streamlit UI
High-level flow:
- User (authenticated) opens the web app with a JWT-protected URL.
- User selects one of the predefined MLB questions from a dropdown (e.g., “What are today’s best 10 bets?”).
- Streamlit backend:
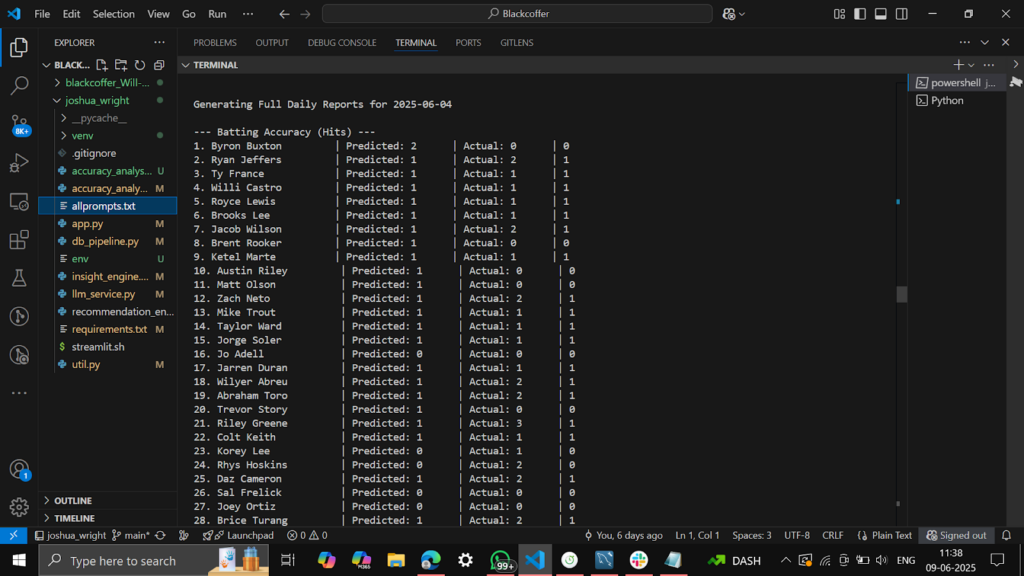
- Loads 5-day rolling data from AWS RDS MySQL using db_pipeline.py
- Merges actual & predicted stats and computes historical accuracies
- Runs the Insight Engine to generate daily text reports & trend summaries
- Packages all of this into a single structured context string for the LLM.
- The question + data context are sent to an OpenAI Assistant via llm_service.py.
- The Assistant is instructed to:
- Use only the data provided
- Skip entries where either actual or predicted values are missing
- Never invent lines or outcomes
- The response is displayed back in Streamlit as a chat-style answer, while the app preserves chat history in session.
Deliverables
- Production-ready Streamlit Web App
- JWT-secured
- Dropdown-based Q&A flow
- Chat-style interface with persistent session state
- AWS RDS Data Integration
- Batting, pitching, match winner, summary, and 4 prediction tables wired into a unified pipeline.
- Historical Accuracy Engine
- Merged actual vs predicted tables
- Accuracy flags per metric (hits, HR, SB, total bases, strikeouts, total outs, game totals, winners).
- Insight & Reporting Layer
- 5-day per-day comparison reports (player-wise and game-wise)
- Game-winner, home run, total outs reports with overall accuracy percentages.
- LLM Assistant Integration
- OpenAI Assistant configured with strict, data-only instructions
- Single context string containing all relevant data for the last 5 days plus insights.
- Recommendation Engine (Support Module)
- Logic to build straight bets, alt line bets, and parlays based on ranked predictions and accuracy columns.
Tech Stack
Tools used
- Streamlit – Web UI framework for the betting assistant.
- OpenAI Assistants API – LLM orchestration for chat and reasoning.
- SQLAlchemy + PyMySQL – Database connectivity and querying.
- Pandas – Data manipulation and analysis across all tables.
- PyJWT – JWT verification in the app layer.
Language / Techniques used
- Python : backend
- Modular architecture (db_pipeline, accuracy_analyzer, insight_engine, llm_service, recommendation_engine, util)
- Timezone-aware analysis using US/Eastern for all date filters.
- Rolling N-day (5 days) window selection using intersection of valid dates across actual and prediction tables.
Models used
- OpenAI GPT-4.x / GPT-4.1 / GPT-4o via Assistants API & chat completions:
- Daily trend summaries in insight_engine.py
- Chatbot responses in llm_service.py
- Strict system instructions to avoid hallucination and skip incomplete rows.
Skills used
- Data engineering for sports datasets
- Advanced feature engineering (total bases, derived innings, YRFI/NRFI probabilities)
- Accuracy metric design for player props & game totals
- Prompt & context design for safety-focused LLM usage
- Secure API & JWT-based web app design
- AWS-based deployment and environment management
Databases used
- AWS RDS – MySQL database
Web / Cloud Servers used
- AWS EC2 instance hosting the Streamlit app and backend code
- AWS RDS for MySQL database
What are the technical Challenges Faced during Project Execution:
Aligning actual vs predicted data from multiple tables
- Different schemas, column names, and keys across 8+ tables
- Needed consistent keys (date, player, team, game_id) for merges.
Multi-day completeness & rolling 5-day window
- Some dates existed in certain tables but not others
- Needed a robust way to pick only those dates where all sources had data.
Accuracy labeling at prop level
- Needed a rule that matched the betting logic:
- “Prediction is counted as correct only if predicted ≥ 1 and actual ≥ predicted.”
- “Prediction is counted as correct only if predicted ≥ 1 and actual ≥ predicted.”
- Separate logic for hits, HR, RBI, SB, TB, strikeouts, total outs, game totals.
YRFI/NRFI logic
- Needed to compute combined first-inning run probabilities per game using team-wise historical tendencies.
Preventing LLM hallucinations
- LLMs naturally want to “fill gaps”
- We needed the assistant to never invent a prediction line or player result if either actual or predicted values were missing.
JWT Authentication only via URL (no manual entry)
- Token had to be read directly from query params
- App must hard-fail when token is missing/invalid (no fallback / no debug leakage).
Strict dropdown-only questions
- Client requirement: lock the assistant to an approved question list
- Needed to keep existing code structure but ensure zero freeform user text.
How the Technical Challenges were Solved
Consistent schema & merges
- Normalized all column names to lowercase with _ separators.
- Explicit renaming:
- player_name → player, h → hits for batting
- Derived total bases from hits, doubles, triples, HR
- For pitching, derived actual_total_outs from innings pitched.
- player_name → player, h → hits for batting
Robust rolling 5-day window
- Implemented get_last_n_valid_dates_for_all_sources() to find dates where both actual and prediction tables had valid data.
- Filtered all tables by this common date list.
Accuracy labels & bet outcome tagging
- accuracy_analyzer.py applies generic functions like label_player_prop_accuracies() across props with configurable bet lines (0.5, 1.5 hits, etc.).
- Added over/under outcome columns (e.g., outcome_hits_o0p5, outcome_gametotal_u8p5).
Game winner & game total accuracy
- Unified names for winning_team_actual and winning_team_pred and labeled winner_prediction_correct and outcome_winner_pick.
- Computed actual_total_score vs predicted_total_score and attached accuracy + over/under outcomes.
YRFI/NRFI aggregation
- Calculated first-inning run probabilities at team level and combined them per game using 1 – (1 – p_team1) * (1 – p_team2).
- Produced a clean table with combined_yrfi_prob and combined_nrfi_prob.
LLM safety & non-hallucination
- Assistant instructions explicitly say:
- “If data is missing or incomplete, skip that entry and do not include it.”
- “Do not generate placeholders or assumptions without both actual and predicted values.”
- “If data is missing or incomplete, skip that entry and do not include it.”
- Only a curated data_string (tables + reports + accuracy_percentages) is sent to the LLM, so it cannot query anything outside this context.
Dropdown-only UX
- Replaced freeform st.chat_input with a selectbox containing only approved MLB questions.
- The selected text is treated as the user query, and nothing else can be typed.
JWT-only access
- Verified token purely from query params.
- On any error (expired/invalid/no token), the app shows a generic “User not verified” error and stops execution.
Business Impact
>90% historical alignment
- Recommendations are based only on historical actual vs predicted data, with labeled accuracy and daily comparison reports to verify performance.
Single source of truth for past performance
- All MLB predictions and outcomes for the last 5 valid days are centralized, cleaned, and merged into a single analytics pipeline.
Faster decision-making
- Bettors and analysts no longer have to manually cross-check spreadsheets.
- They can instantly ask, for example:
- “What are today’s best 10 bets?”
- “Build me 3 parlays for high accuracy today.”
- “Who are top HR candidates for today?”
- “What are today’s best 10 bets?”
Reduced risk from hallucinating AI
- The LLM cannot “invent” numbers—it is boxed into the provided data, improving trust and adoption.
Extensible foundation for future features
- Existing modules can be extended to longer historical windows, live odds, or sportsbook integration with minimal structural change.
Project Snapshots :

Project Video:
URL:




 Tool using BERT")






