


Data Infrastructure: Starting with Small.
If you have less than 5TB of data, start small. This will save you operational headaches with maintaining systems you don’t need yet. Focus on two things:
- making your data queryable in SQL, and
- choosing a BI Tool.
These will be the backbone for all of your future data infrastructure.
Everything in SQL
This is really important because it unlocks data for the entire organization. With rare exceptions for the most intrepid marketing folks, you’ll never convince your non-technical colleagues to learn Kibana, grep some logs, or to use the obscure syntax of your NoSQL datastore.
Providing SQL access enables the entire company to become self-serve analysts, getting your already-stretched engineering team out of the critical path. It also turns everyone into a free QA team for your data.
If your primary data store is a relational database such as PostgreSQL or MySQL, this is really simple. You can just set up a read replica, provision access, and you’re all set.
With a NoSQL database like ElasticSearch, MongoDB, or DynamoDB, you will need to do more work to convert your data and put it in a SQL database. If you’re new to the data world, we call this an ETL pipeline.
If you find that you do need to build your own data pipelines, keep them extremely simple at first. Write a script to periodically dump updates from your database and write them somewhere queryable with SQL.
The story for ETL-ing data from 3rd party sources is similar as with NoSQL databases. Use an ETL-as-a-service provider or write a simple script and just deposit your data into a SQL-queryable database. Set up a machine to run your ETL script(s) as daily corn, and you’re off to the races.
BI Tool
A good BI tool is an important part of understanding your data. Some great tools to consider are Chartio, Mode Analytics, and Periscope Data — any one of these should work great to get your analytics off the ground. In most cases, you can point these tools directly at your SQL database with a quick configuration and dive right into creating dashboards.

Data Infrastructure: Going Big
At this point, you’ve got more than a few terabytes floating around, and your cron+script ETL is not quite keeping up. Perhaps you’ve proliferated datastores and have a heterogeneous mixture of SQL and NoSQL backends. You may also now have a handful of third parties you’re gathering data from. Finally, you may be starting to have multiple stages in your ETL pipelines with some dependencies between steps.
Workflow Management & Automation
Your first step in this phase should be setting up Airflow to manage your ETL pipelines. Airflow will enable you to schedule jobs at regular intervals and express both temporal and logical dependencies between jobs. It is also a great place in your infrastructure to add job retries, monitoring & alerting for task failures.
Building ETL Pipelines
As your business grows, your ETL pipeline requirements will change significantly. You will need to start building more scalable infrastructure because a single script won’t cut it anymore. Your goals are also likely to expand from simply enabling SQL access to encompass supporting other downstream jobs which process the same data.
To address these changing requirements, you’ll want to convert your ETL scripts to run as a distributed job on a cluster. The number of possible solutions here is absolutely overwhelming. I’d strongly recommend starting with Apache Spark. Spark has a huge, very active community, scales well, and is fairly easy to get up and running quickly. On Google Cloud, you can run Spark using Cloud Dataproc. If you’re ingesting data from a relational database, Apache Sqoop is pretty much the standard.
At this point, your ETL infrastructure will start to look like pipelined stages of jobs which implement the three ETL verbs: extract data from sources, transform that data to standardized formats on persistent storage, and load it into a SQL-queryable datastore.
Data Warehouse
At this stage, getting all of your data into SQL will remain a priority, but this is the time when you’ll want to start building out a “real” data warehouse.
I’d recommend using BigQuery (Google Cloud has it). BigQuery is easy to set up (you can just load records as JSON), supports nested/complex data types, and is fully managed/serverless so you don’t have more infrastructure to maintain. I have a strong preference for BigQuery over Redshift (AWS) due to its serverless design, the simplicity of configuring proper security/auditing, and support for complex types.
When thinking about setting up your data warehouse, a convenient pattern is to adopt a 2-stage model, where unprocessed data is landed directly in a set of tables, and a second job post-processes this data into “cleaner” tables.
Treat these cleaner tables as an opportunity to create a curated view into your business. For each of the key entities in your business, you should create and curate a table with all of the metrics/KPIs and dimensions that you frequently use to analyze that entity. For example, a “users” table might contain metrics like signup time, number of purchases, and dimensions like geographic location or acquisition channel.
At the end of all this, your infrastructure should look something like this:
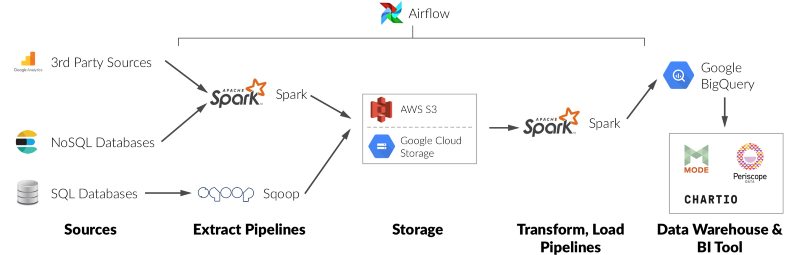
With the right foundations, further growth doesn’t need to be painful. You can often make do simply by throwing hardware at the problem of handling increased data volumes.
Analytics
The most challenging problems in this period are often not just raw scale, but expanding requirements. For example, perhaps you need to support A/B testing, train machine learning models, or pipe transformed data into an ElasticSearch cluster.
Some things you may want to consider in this phase:
Near-Realtime
You probably won’t need a distributed queue or near-realtime infrastructure until much later than you might think. It comes with a lot of added complexity to handle all possible failure modes, which isn’t worth it early on. Once the ROI calculus makes sense, try Kafka or Cloud Pub/Sub.
Scalability
With a single monolithic Spark cluster, you’ll almost certainly run into issues with resource contention. When you do, fully elastic job-scoped Spark clusters are worth exploring.
Security & Auditing
At some point, you may want to enforce more granular access controls to your data warehouse data. If you use BigQuery, you can provision dataset access to Google Groups, and programmatically manage that access using Deployment Manager. BigQuery also provides audit logs to understand user queries. Other tools like Apache Knox and Apache Sentry are available for on-prem security solutions.
A/B Testing
For building in-house A/B testing and supporting experimentation, there, unfortunately, are not many off-the-shelf solutions. Building a pipeline of Spark jobs that populate tables in your data warehouse is probably your best bet.
Machine Learning
For feature extraction, you can build additional data pipelines in Spark. For the models themselves, you should again start small. Your processed features are likely small enough to fit on one machine so you can train models using sci-kit-learn or TensorFlow. When one machine is no longer enough, you can use Spark MLlib or distributed TensorFlow.
****










")
")