

Client Background
Client: A leading Research institution in the USA
Industry Type: Research
Services: R&D
Organization Size: 10,000+
Project Objective
Objective of this project is to mine and extract data from Sotheby’s auction website, process data, clean and store the extracted data into an excel spreadsheet in analytics ready format.
Project Description
This project is basically completed using Selenium and Scrapy. All we have done is write a python script to crawl the data in which we are interested, after that use scrapy to download all images using image urls.
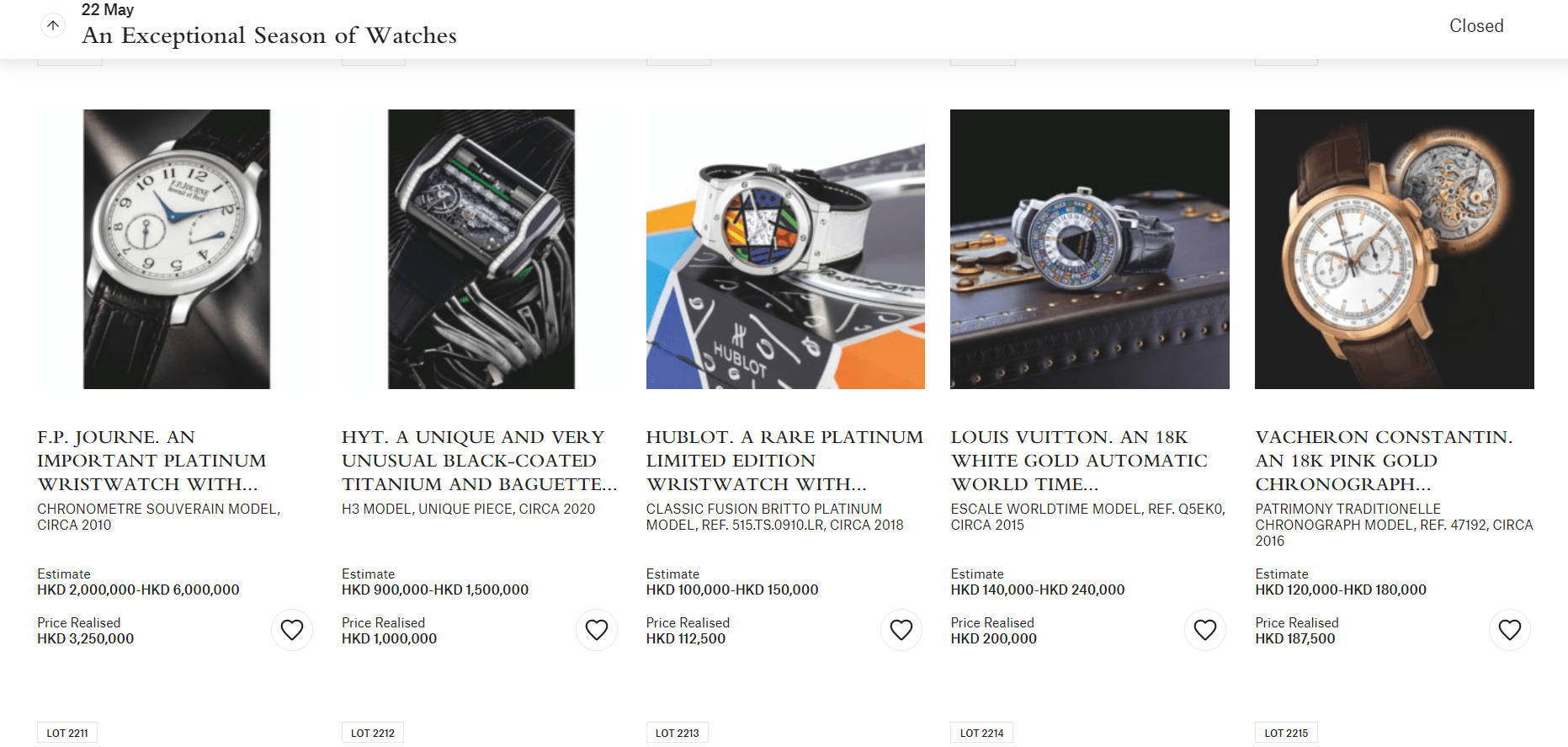
The fields or details crawl for each watch are:
- URL of Image of the Watch (multiple)
- Watch Brand Name (eg. AUDEMARS PIGUET)
- Watch Description (eg. A FINE YELLOW GOLD, RUBY AND DIAMOND BRACELET WATCH CIRCA 2000 ROYAL OAK NO 2607)
- Detailed Description (eg. • quartz movement • red mother-of-pearl dial, calibré-cut ruby numerals at 12, 6 and 9, diamond set numerals at the intervals, aperture for date • 18k yellow gold satin finished case, screwed down octagonal bezel set with 24 calibré-cut rubies • integrated 18k yellow gold satin finished Royal Oak bracelet and folding clasp • case, dial, movement and bracelet signed)
- Watch Dimensions (eg. WIDTH 33MM, LENGTH OVERALL 190 MM)
- Estimate price (eg. USD 12,000 — 18,000)
- Lot Sold (eg. USD 15,000)
- Auction Location and Date (eg. Doha 19 March 2009)
- Condition Report (available only after signing up)
Our Solution
A simple python code which uses selenium web driver to crawl data from website. Also a scrapy tool to download images.
Project Deliverables
- Python Tool
- Data
- Watch Images
Tools used
- Selenium Webdriver
- Scrapy
Language/Techniques used
- Python
Skills used
- Web Scraping
- Selenium
- Scrapy
Databases used
NoSql
Web Cloud Servers used
Google Cloud Platform
Project Snapshots

Project ebsite URL
https://www.sothebys.com/en/results?from=&to=&f2=00000164-609a-d1db-a5e6-e9fffc050000&q=





 Tool using BERT")





