


Client Background
- Client: A leading IT & Tech firm in USA
- Industry Type: IT & Data Service
- Products & Services: Data Analysis
- Organization Size: 70+
The Problem
Organizations often manage large volumes of scanned documents in the form of PDFs and JPEGs, which are unstructured and difficult to process manually. Extracting relevant information, categorizing content, and tagging documents for downstream integration (e.g., with ERP systems) is typically time-consuming, error-prone, and requires significant manual effort. This inefficiency leads to delays, misclassification, and increased operational costs, especially in document-heavy industries such as finance, healthcare, and logistics.
Our Solution
Designing and developing a FastAPI-based document processing pipeline that automates the extraction, categorization, and tagging of scanned documents (PDFs and JPEG images). The system will utilize advanced OCR capabilities and AI-driven classification to accurately process and label documents into predefined categories, facilitating integration with downstream systems such as ERPs.
Solution Architecture
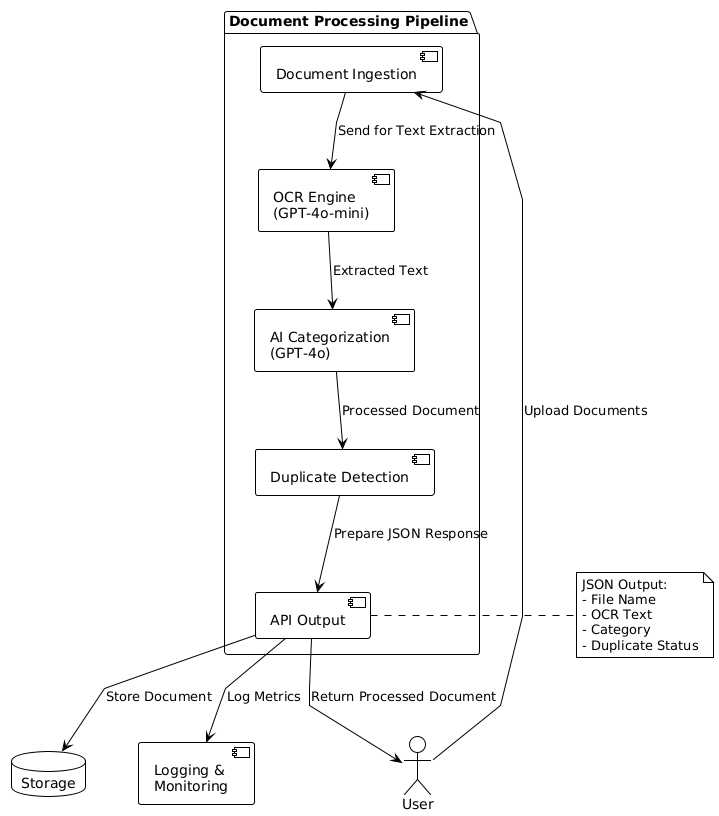
Deliverables
- FastAPI-based backend pipeline with the following endpoints:
- /process_documents for document processing.
- OCR and categorization integrated using GPT-40-mini and GPT-4.
- JSON-based structured output for integration.
- Deployment-ready solution.
- API documentation (Swagger or Postman collection).
- Error logs and monitoring tools.
Tech Stack
- Tools used
- FastAPI and OCR
- Language/techniques used
- Python
- Models used
- OpenAI GPT 4o and 4o-mini
- Skills used
- AI, Python, Prompt Engineering
- Databases used
- Local storage
- Web Cloud Servers used
- Azure
What are the technical Challenges Faced during Project Execution
During the development of the FastAPI application, we faced some technical challenges. One major issue was handling bulk PDF uploads. The system processes files one by one, which made it slow and caused delays. We also faced rate limit problems when too many files were uploaded at once, making the system laggy. As a result, the documents were not always categorized properly by the AI model.
How the Technical Challenges were Solved
We solved the technical challenges by using asynchronous methods. This allowed us to handle PDF uploading, OCR text extraction, and processing with the OpenAI model efficiently. We also used bulk prompts to process all the extracted content at once, making the categorization faster and more effective.
Business Impact
The automated document processing system improves efficiency by quickly extracting, categorizing, and tagging scanned documents. This reduces manual work, speeds up operations, and enables seamless integration with ERP systems, leading to better data management and faster decision-making.
Project Snapshots
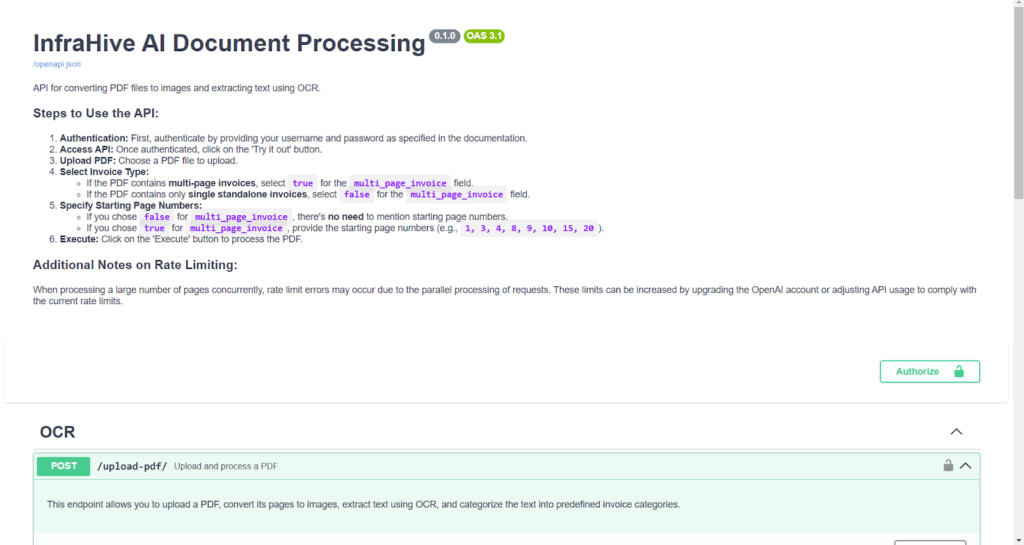
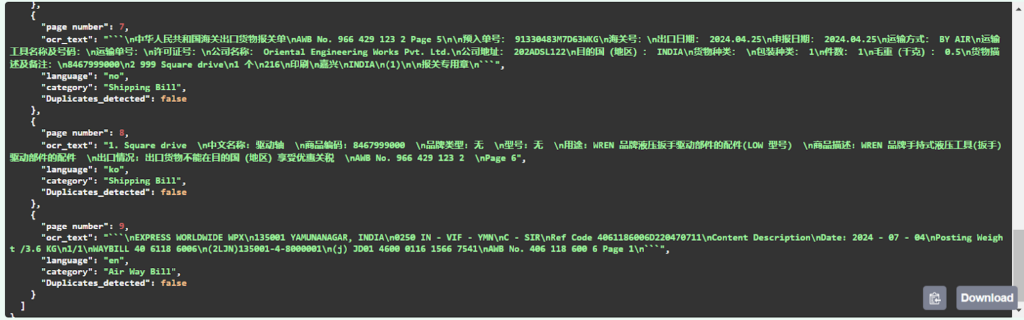
Project website url
http://4.240.101.229:8000/docs#




 Tool using BERT")


 Leads Dashboard")



