


Client Background
- Client: Education and Research Institute in USA
- Industry Type: Research Institute
- Products & Services: Education
- Organization Size: 500+
The Problem
The problem is to collect data on all the apps listed on Salesforce AppExchange, starting in January 2025 and continuing once a month through December 2026. Our goal is to track changes over time. However, we haven’t found an official API that lets us access this data directly. The available Salesforce APIs don’t seem to work for AppExchange. So, the only way we’ve found to collect the data is by scraping it from the AppExchange website.
Our Solution
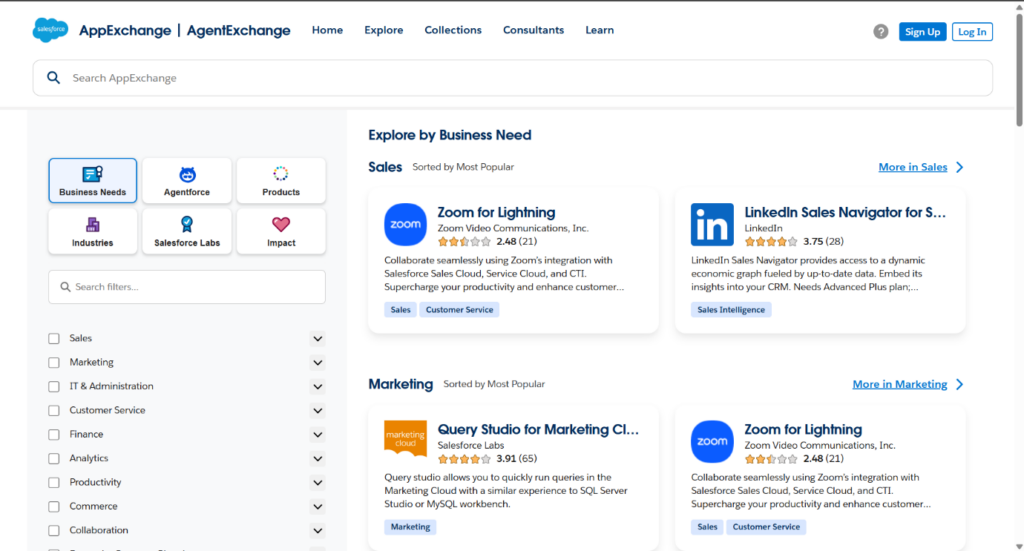
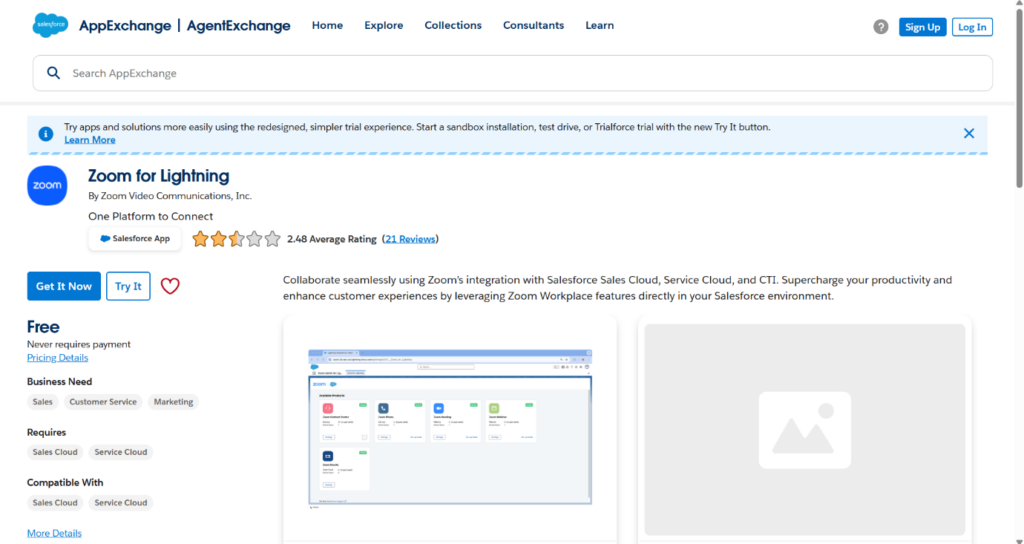
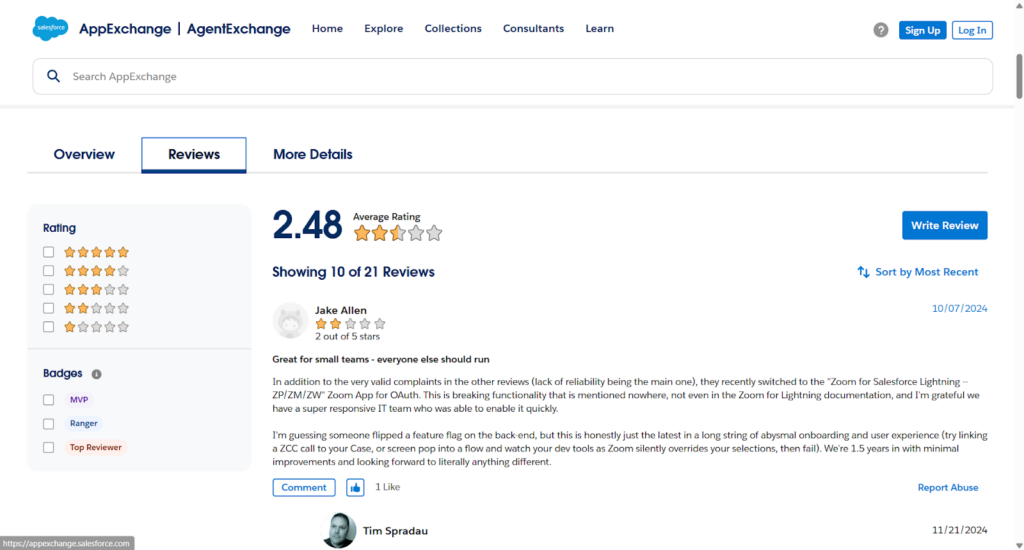
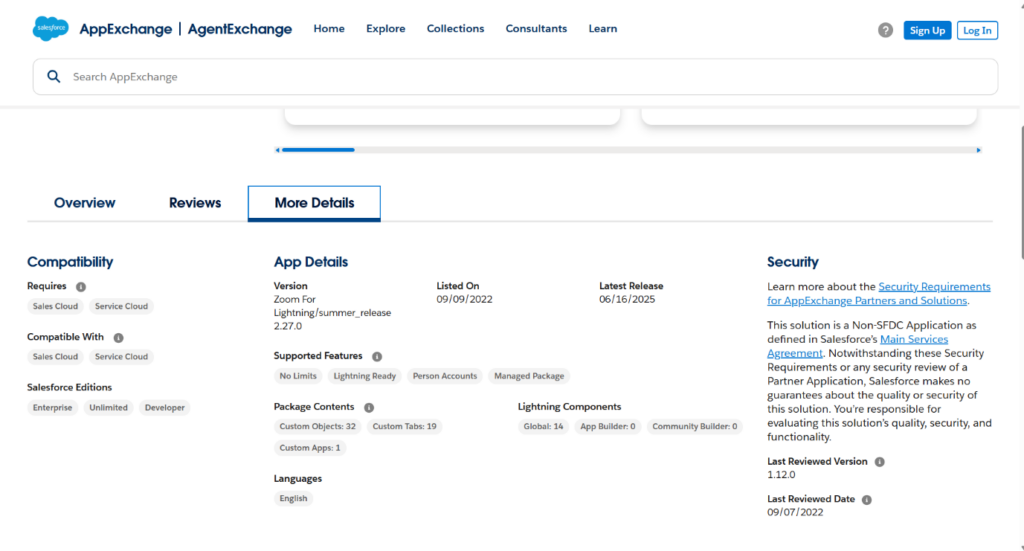
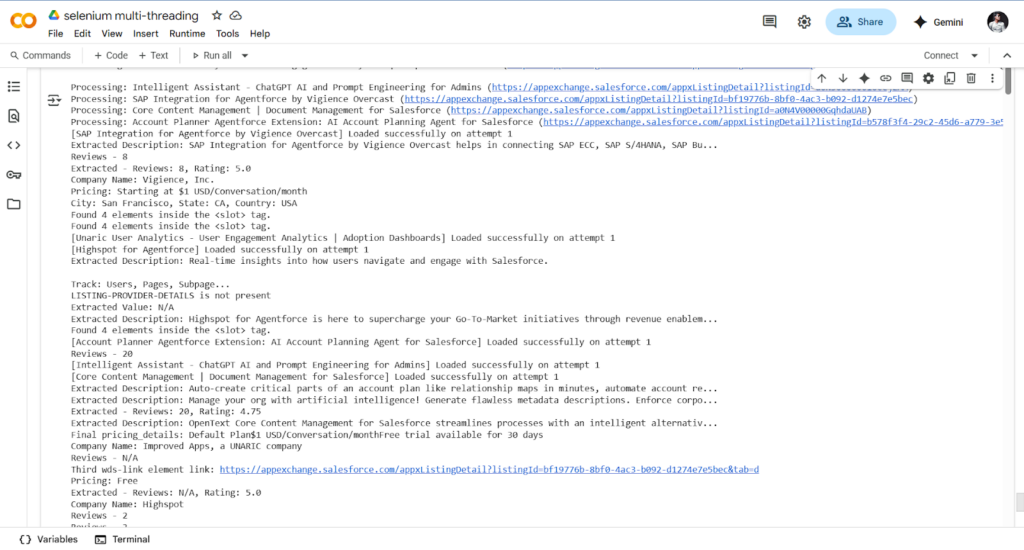
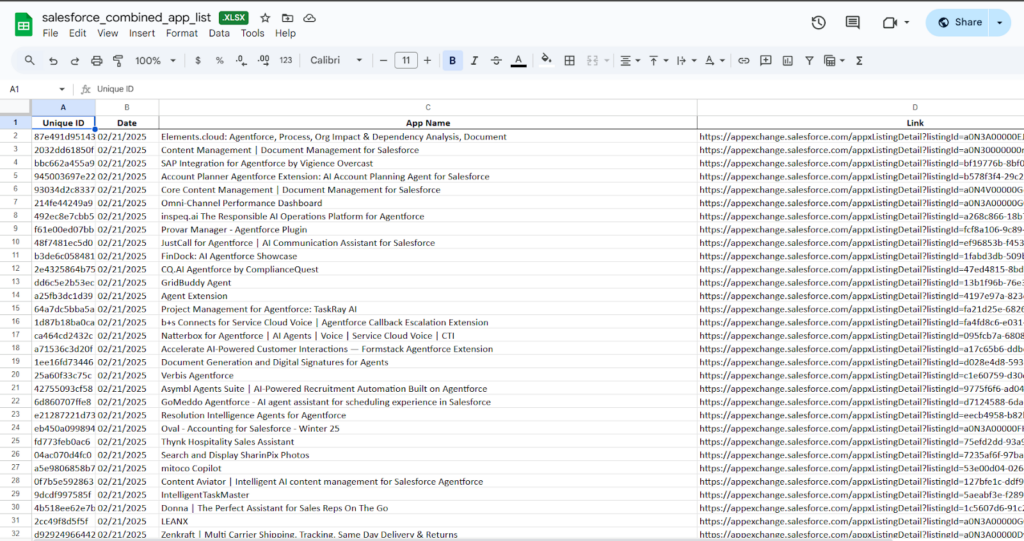
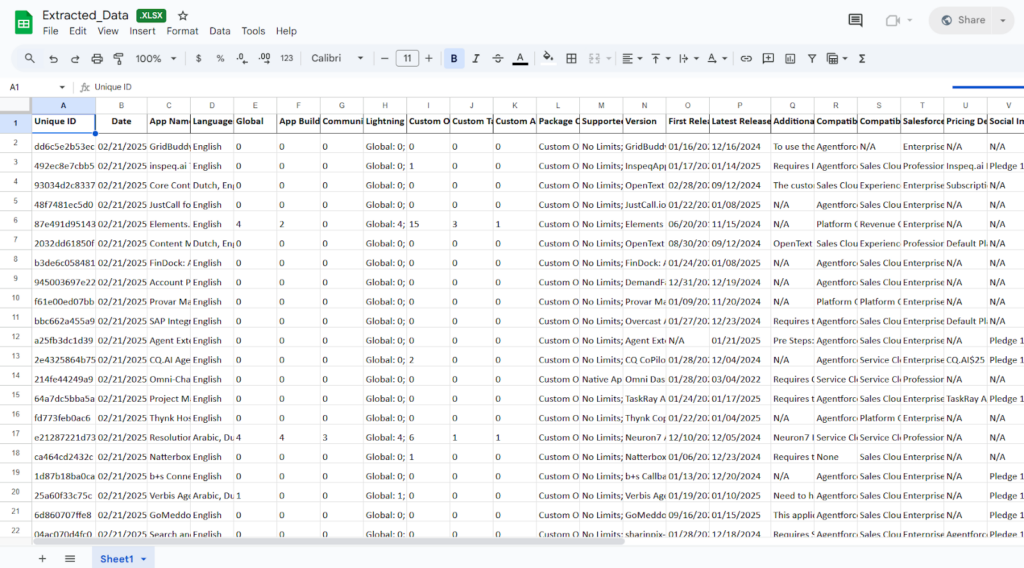
To solve this, we will build a web scraper that automatically collects data from the Salesforce AppExchange website. This scraper will run once a month from January 2025 to December 2026. It will gather information on all available apps, such as app names, descriptions, categories, ratings, number of reviews, and other key details. The collected data will be saved in a structured format (like in Excel or CSV file) so we can track how the AppExchange data changes over time
Deliverables
One Time Output data in CSV / Excel
Monthly updated output data
Source code
Documentation and updated data every month end
Tech Stack
- Tools used
- Selenium web scraping tool
- Language/techniques used
- Python, web scraping
- Models used
- No model used
- Skills used
- Python, selenium, automation tool, web scraping, excel
- Databases used
- No database is used
- Web Cloud Servers used
- No web cloud servers used
What are the technical Challenges Faced during Project Execution
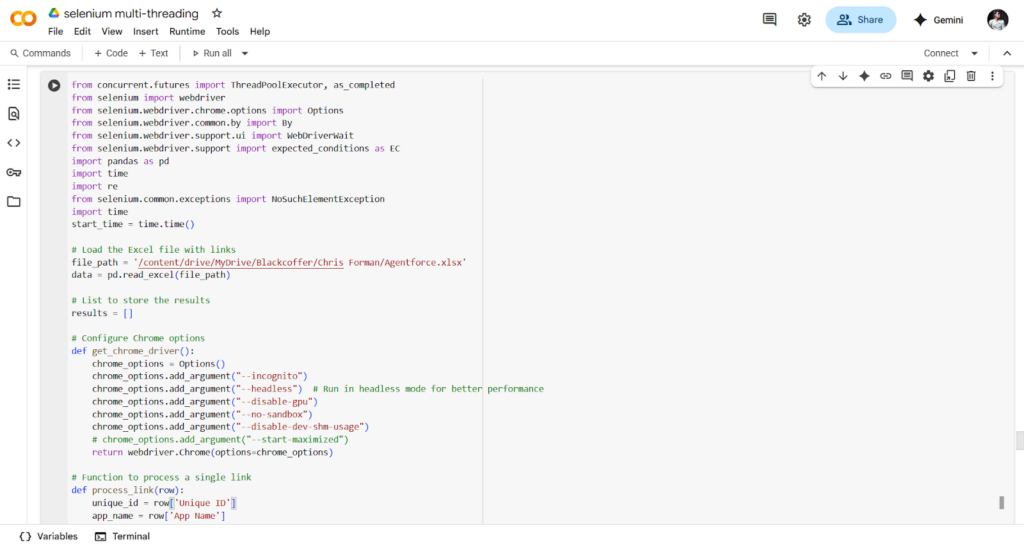
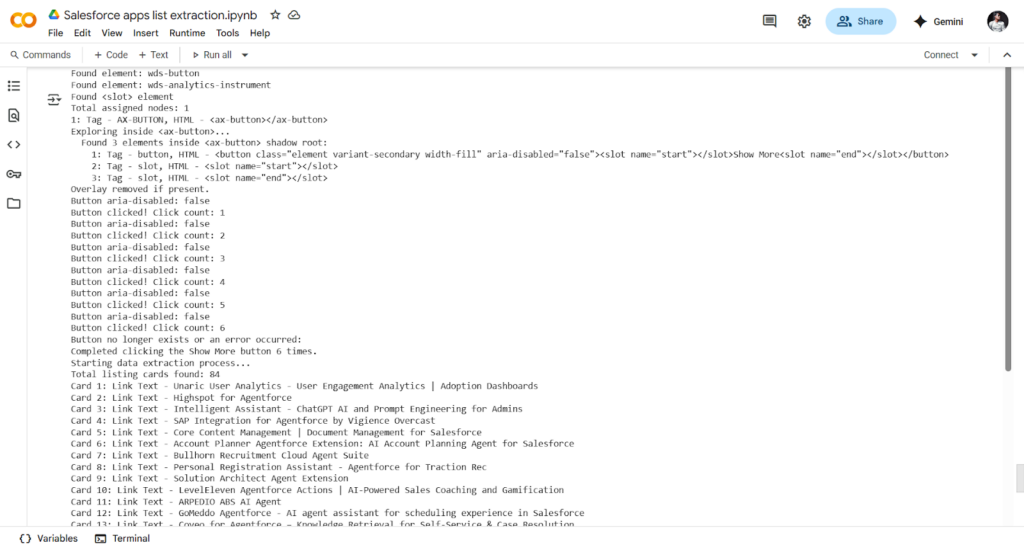
The main technical challenge we faced was the structure of the AppExchange website. It’s built using complex DOM elements, including many shadow-root elements. These are like hidden layers in the web page that are harder to access with normal scraping tools. On top of that, there are slotted elements mixed in, which spread the content across different parts of the page.
How the Technical Challenges were Solved
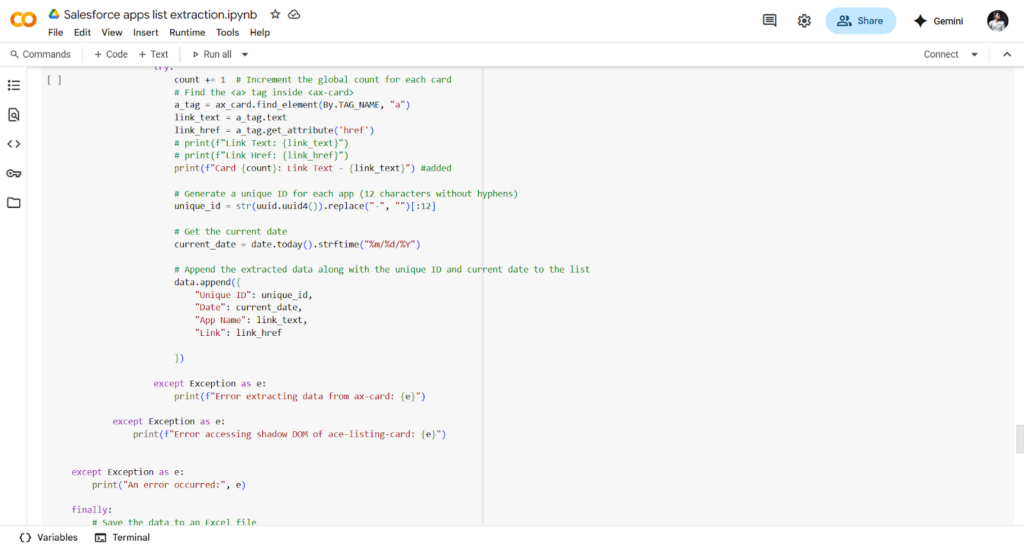
We solved the challenge by writing selenium code in python that could open and access the shadow root elements. Once we did that, we were able to move to the next elements on the page. For the slotted elements and their distributed content, we used a loop to go through each of them one by one. This allowed us to reach and extract the hidden data and continue navigating the rest of the website to collect the app information.
Business Impact
By developing a custom web scraper for Salesforce AppExchange, we are able to collect comprehensive app data consistently and reliably without relying on official APIs or API keys. This eliminates the risk of service interruptions, access limitations, or changes in third-party API policies. As a result, we can build a robust, month-by-month dataset from January 2025 to December 2026 that supports long-term analysis, trend tracking, market insights, and strategic decision-making—providing a valuable competitive edge and data independence.
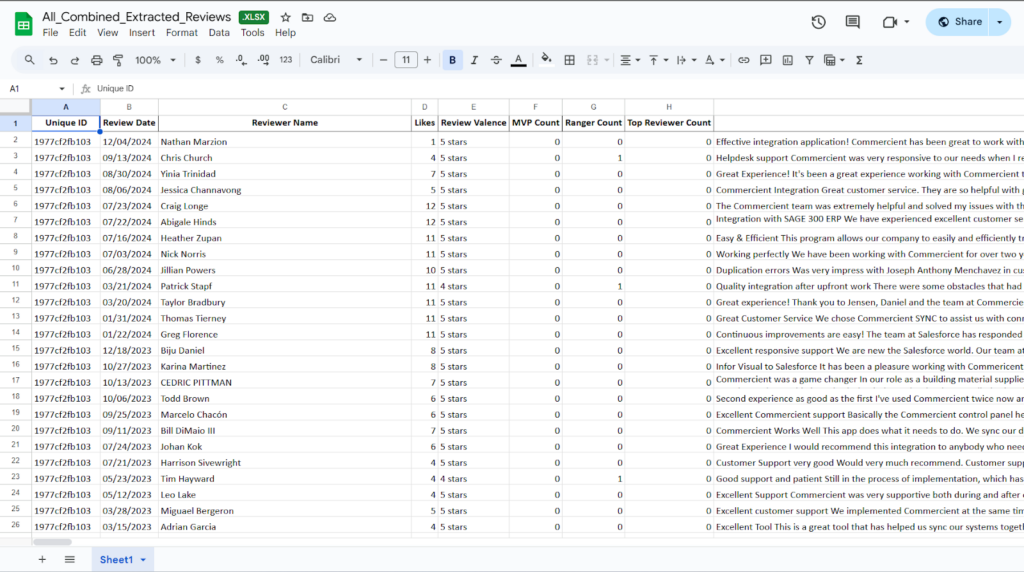
Project Snapshots










")








