


Client Background
Client: A leading medical R&D firm in the USA
Industry Type: Medical
Products & Services: R&D
Organization Size: 10000+
The Problem
An advanced AI tool designed specifically for doctors to assist them in retrieving answers to their
queries. Powered by state-of-the-art AI technologies, including web scraping and ChatGPT, The AI
Assistant aims to streamline information retrieval and provide valuable insights to professionals.
This AI Assistant leverages the capabilities of AI to facilitate seamless and efficient access to
knowledge and information. It combines web scraping techniques to gather relevant data from
trusted sources with ChatGPT and PubMed, providing accurate responses to doctors’ queries.
Query Retrieval: AI Assistant utilizes web scraping techniques to fetch information from credible
websites, academic journals, medical databases, and other trusted sources. It provides doctors with
immediate access to a vast array of knowledge and resources.
Benefits:
Time Efficiency: By quickly retrieving information and answering queries, AI Assistant saves
valuable time for doctors, allowing them to focus more on patient care and critical tasks.
Access to Knowledge: AI Assistant grants doctors easy access to a vast repository of knowledge,
ensuring they stay updated with the latest research, treatment guidelines, and best practices.
Decision Support: The tool provides valuable insights and recommendations, assisting doctors in
making informed decisions about diagnosis, treatment plans, and patient management.
Our Solution
To address this problem, we will build a web scraping tool that uses Python libraries such as BeautifulSoup, Selenium, and OpenAI’s GPT-3. The program will work as follows:
- A user inputs the URL of the case report they want to extract data from.
- The program sends a GET request to the webpage and parses the HTML content using BeautifulSoup.
- The program then identifies the relevant sections of the webpage (such as the title, introduction, report, conclusion, and keywords) and extracts the text content.
- For each reference linked in the case report, the program sends a GET request to the reference’s webpage and parses the HTML content.
- The program then sends a prompt to the GPT-3 model, asking it to summarize the content of the reference, and receives a summarized response.
- The program collects all the summarized references and adds them to the case report.
- The program also identifies any images associated with the case report and downloads them.
- Finally, the program creates a Word document and adds all the collected information (including the summarized references and downloaded images) to the document.
Solution Architecture

Deliverables
- A fully functional web scraping tool that can extract data from a given webpage and generate a case report.
- A detailed documentation explaining how to use the tool and what kind of data it can extract.
Tech Stack
- Tools used
- Python
- BeautifulSoup
- Selenium
- OpenAI’s GPT-3
- Language/techniques used
- Python
- Models used
- OpenAI’s GPT-3
- Skills used
- Web Scraping
- Natural Language Processing
- Machine Learning
What are the technical Challenges Faced during Project Execution
- Handling dynamic websites that load content via JavaScript.
- Managing rate limits and CAPTCHAs imposed by the target websites.
- Ensuring the accuracy and relevance of the summarized content generated by the GPT-3 model.
How the Technical Challenges were Solved
- Using Selenium to interact with the JavaScript-rendered content of the target websites.
- Implementing strategies to bypass rate limits and CAPTCHAs.
- Fine-tuning the parameters of the GPT-3 model to improve the quality of the summarized content.
Business Impact
The implementation of our web scraping and summarization tool has had significant positive impacts on our business operations.
Firstly, it has streamlined our research process by automating the extraction of crucial information from various online sources. This has saved us considerable time and effort, allowing us to focus on more complex tasks.
Secondly, the summarization feature has improved our understanding of the information we collect. By reducing large volumes of text down to a few key points, we’ve been able to quickly grasp the main ideas and insights presented in the articles, videos, and user comments.
Thirdly, the tool has enabled us to stay up-to-date with the latest advancements in the field of orthopedics. By pulling data from recent articles on PubMed.gov, we’ve been able to stay informed about the latest research and treatments.
Finally, the tool has facilitated the creation of comprehensive case reports. These reports have been instrumental in our ability to present detailed and accurate information to our clients, thereby enhancing our reputation and credibility in the industry.
Overall, the implementation of this tool has greatly improved our efficiency and effectiveness, contributing significantly to our business success
Project Snapshots

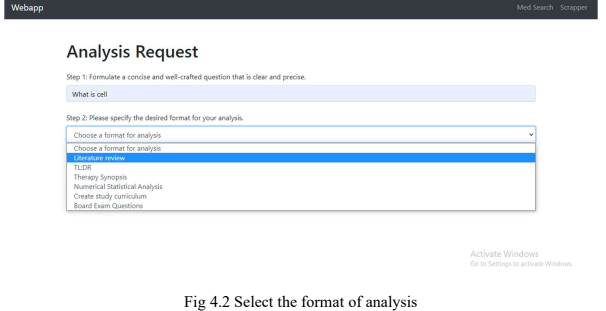
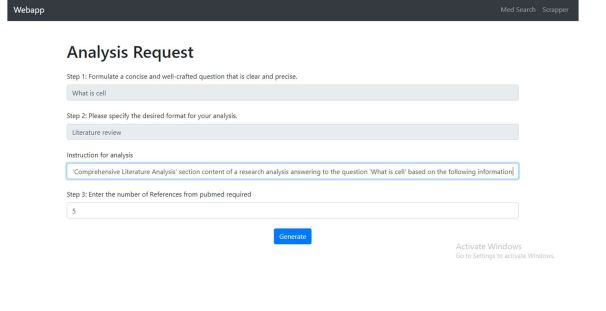

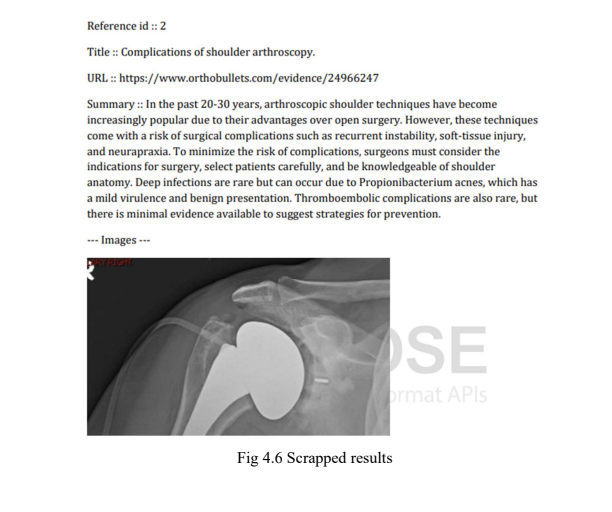
Project Video
Link: https://www.loom.com/share/535828aad7184c1b82db707dcca8e52c?sid=c79d19b1-b963-45a1-bec5-6228cc753cc2
Summarize
Summarized: https://blackcoffer.com/
This project was done by the Blackcoffer Team, a Global IT Consulting firm.
Contact Details
This solution was designed and developed by Blackcoffer Team
Here are my contact details:
Firm Name: Blackcoffer Pvt. Ltd.
Firm Website: www.blackcoffer.com
Firm Address: 4/2, E-Extension, Shaym Vihar Phase 1, New Delhi 110043
Email: ajay@blackcoffer.com
Skype: asbidyarthy
WhatsApp: +91 9717367468
Telegram: @asbidyarthy




 Tool using BERT")






