

")
Platform Brief
This platform requires developing the Voice and SMS modules of the AI-based Voice Assistant platform referred to as the AI Receptionist. The platform must efficiently manage up to 1,0000 calls daily, support up to 1000 concurrent calls, and handle thousands of SMS messages seamlessly. The system architecture should emphasize low latency, precise data capture, and optimized retrieval mechanisms. To ensure rapid development and scalability, the implementation strategy should prioritize the integration of plug-and-play APIs over custom-built components. The proposed development approach is detailed below for review and consideration.
Solution Architecture
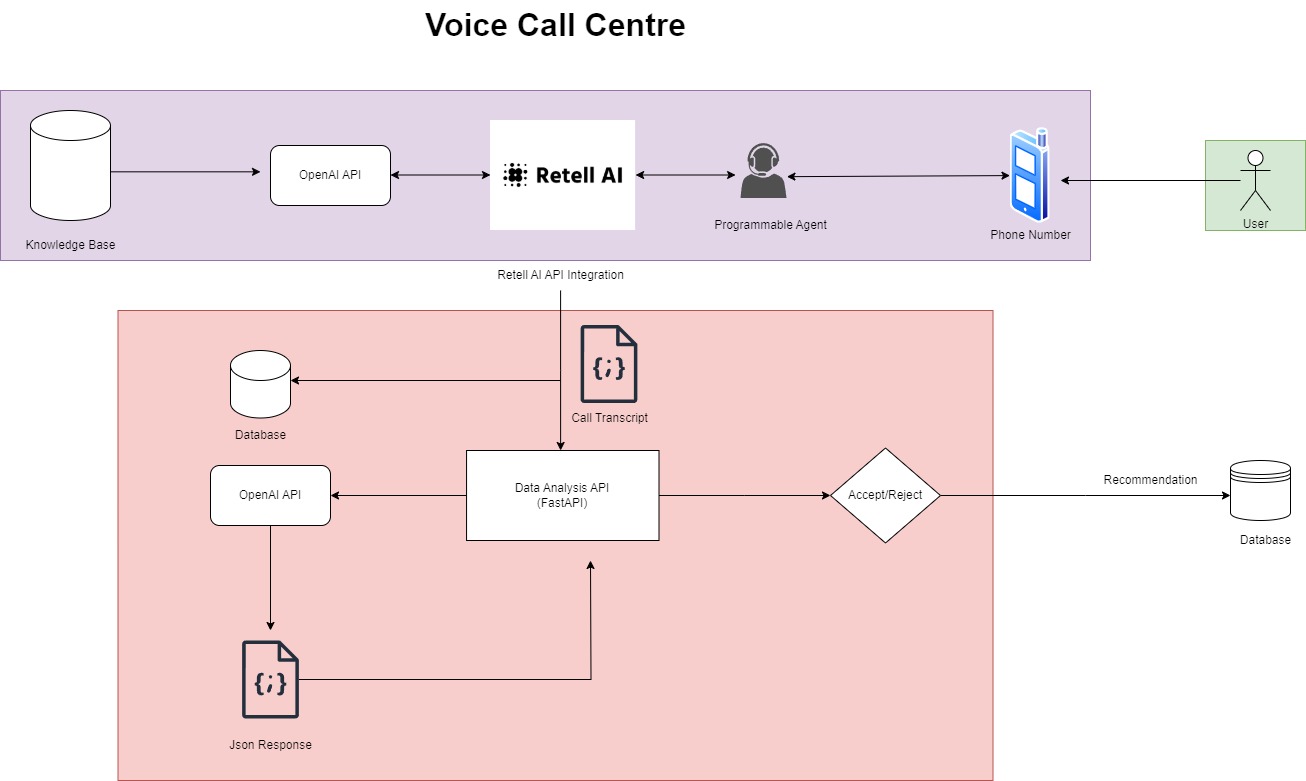
Platform Work Flow Architecture
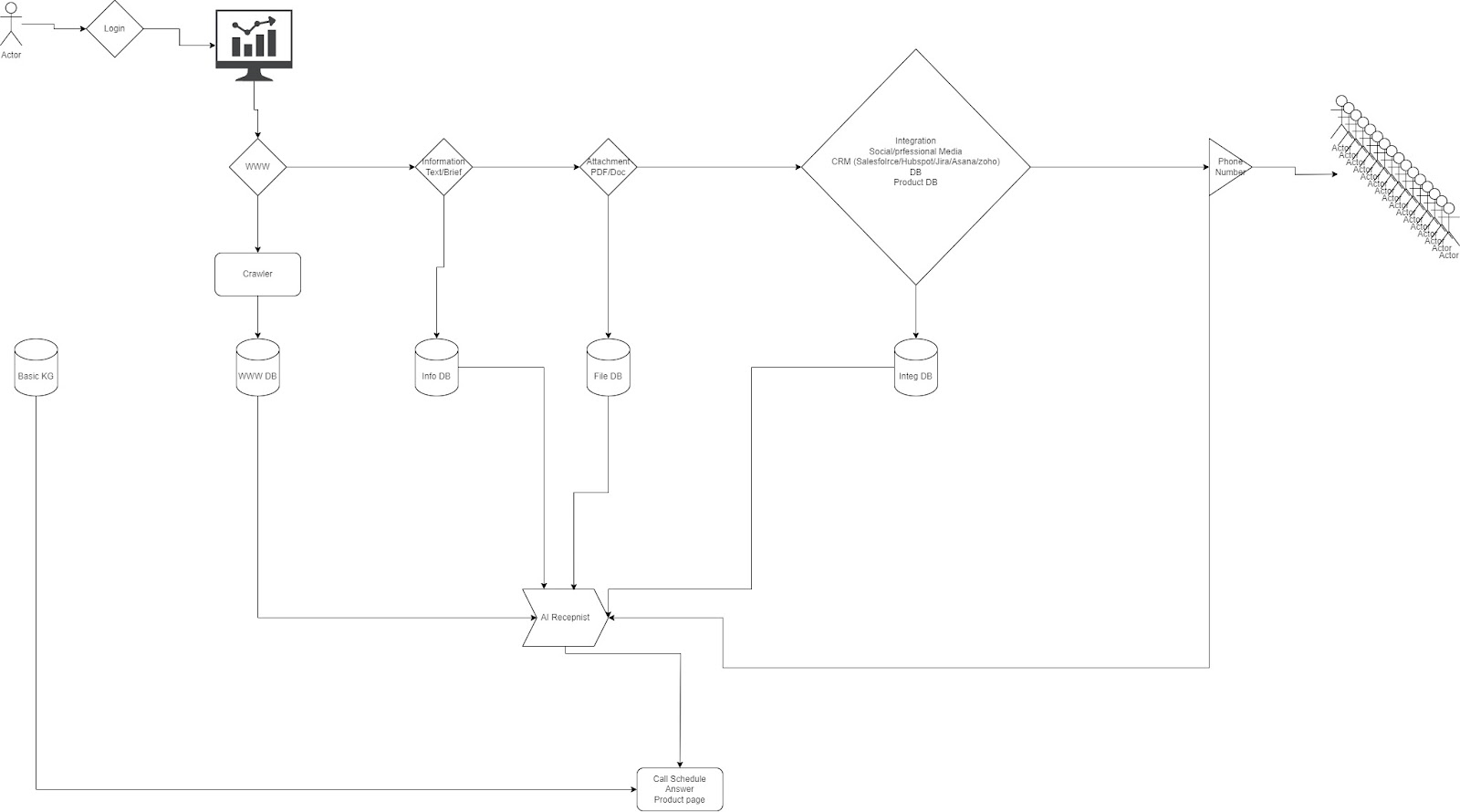
Platform Components
LiveKit: An open-source platform for real-time video, audio, and data communication. In the VoiceMate platform, LiveKit functions as the central hub for managing user interactions during voice calls. It handles real-time audio routing, connecting incoming and outgoing voice streams between the user and the Voice Agent. Additionally, LiveKit integrates seamlessly with external services such as Deepgram, OpenAI Audio Models, and OpenAI LLM, enabling features like speech-to-text, text-to-speech, and conversational intelligence. Each call is assigned to a dedicated “room,” ensuring isolated, uninterrupted sessions with synchronized audio capture for user-agent dialogues.
Alternatives:
– Vapi AI
– Retell AI
Twilio: Manages SMS, MMS, media, and inbound/outbound voice calls. It facilitates call routing to LiveKit for user interaction and real-time audio capture.
Deepgram: Integrated via LiveKit, Deepgram provides speech-to-text conversion, transcribing user and agent speech during calls for analysis and processing.
OpenAI LLM: Embedded within LiveKit, the OpenAI LLM delivers conversational intelligence, generating contextually relevant responses from conversation data. In VoiceMate, the LLM enhances interactions by creating dynamic responses, generating embeddings, and contributing to retrieval-augmented generation (RAG) for greater contextual precision.
OpenAI Audio Models: This text-to-speech service, integrated through LiveKit, converts LLM-generated text responses into natural-sounding speech, ensuring a seamless and engaging user experience.
Amazon S3: Provides scalable and secure storage for call data, including audio recordings, transcriptions, and LLM responses.
Pinecone: Manages vectorized conversation data, enabling fast retrieval of relevant information to maintain contextual continuity during follow-up interactions.
PostgreSQL: Stores application metadata, such as references to call data in S3, vector data in Pinecone, and initial LLM response mappings, supporting efficient data retrieval and management.
Data collection and storage
Text-Based Data:
- Use Deepgram to separately capture user and agent speech as text.
- Record SMS text data for reference.
- Store all LLM-generated responses as text.
Audio Capture:
- Store the complete audio conversation sequentially, ensuring no interruptions or omissions.
MMS (Images) and Media (Video):
- Receive, download, and securely store MMS messages and images.
- Support and store media files such as mp4 and 3GP formats.
Embeddings:
- Generate embeddings for the entire conversation, including both user and agent speech, while excluding LLM responses to preserve the context of the interaction.
Data Storage and Retrieval:
- Efficiently store audio files, transcriptions, and embeddings to facilitate seamless retrieval for future interactions, such as when a customer calls back.
Workflow
1. Call Initiation
- Upon call initiation, LiveKit assigns a dedicated “room” to handle the interaction between the user and the Voice Agent, ensuring session isolation.
2. Audio Capture
- LiveKit’s API records both user and agent audio streams in real time, capturing the entire conversation accurately and without interruptions.
3. Transcription
- During the call, Deepgram’s Speech-to-Text (STT) is used to create two separate transcription streams: one for user speech and one for agent speech.
- Transcriptions are tagged with roles (e.g., “User” and “Agent”) and timestamps for clarity and context.
Example:
| Time | Speaker | Content |
| 10:00 AM | Agent | Hi, how are you doing? |
| 10:01 AM | User | I am doing okay, and I want to know what your hours of operation are. |
4. Capture LLM Response
- LLM-generated responses are processed through Text-to-Speech (TTS) and separately stored as text, maintaining a clear distinction from user-agent dialogues.
5. Data Storage
- Audio Recordings and Transcriptions: Stored in Amazon S3 for scalability and secure access.
- Metadata: Maintained in PostgreSQL, referencing audio files, transcriptions, and initial LLM responses for efficient tracking and retrieval.
6. Post-Processing
- After the call, a dedicated server processes transcriptions via the LLM to generate summaries, Q&A insights, and additional context.
- This approach offloads intensive tasks from the main application, ensuring optimal responsiveness during live interactions.
7. Embedding Creation
- User and agent dialogue transcriptions are vectorized (excluding LLM responses) using a specialized embedding model.
- The resulting vectors are stored in Pinecone for efficient retrieval during future interactions.
8. Business Owner Embeddings
- A dedicated Pinecone index is created for each business to store business-specific embeddings, including owner instructions, operational data, and tailored prompts.
- These embeddings enable personalized responses aligned with the business’s unique requirements.
9. Contextual Retrieval
- Upon a follow-up call, the system retrieves:
- Call Metadata: From PostgreSQL.
- User and Call Embeddings: From the “call recordings” index in Pinecone.
- Business-Specific Embeddings: From the corresponding Pinecone index.
- Using Retrieval-Augmented Generation (RAG), the system combines these datasets, incorporating business instructions to deliver consistent, contextually accurate responses.
10. Business Domain-Level Embeddings
- A separate index is created in Pinecone for domain-level knowledge shared by similar businesses (e.g., a “Plumbing Industry” index).
- If no relevant data is found in the specific business’s index, the system queries the domain-level index to provide accurate, industry-specific insights.
References
https://docs.livekit.io/sip/quickstart
Frontend Template
web Template
– https://demos.pixinvent.com/vuexy-vuejs-admin-template/demo-1/dashboards/analytics
