

")
Objective
The primary objective of the is to develop a highly efficient AI chatbot tailored for eye care patients. The chatbot will assist in booking appointments, tracking the status of lens orders, reviewing patient dues, sending statements, and answering general questions about their exams and the practice. It will integrate custom-trained QLoRA models using open-source LLMs, Twilio for SMS communication, and Retrieval-Augmented Generation (RAG) for handling confidential data using vector databases like ChromaDB. The AI related APIs will be developed using FastAPI/Flask, and additional functionalities such as booking, appointment handling, dues management, and order tracking will be managed by the backend system.
Solution Architecture
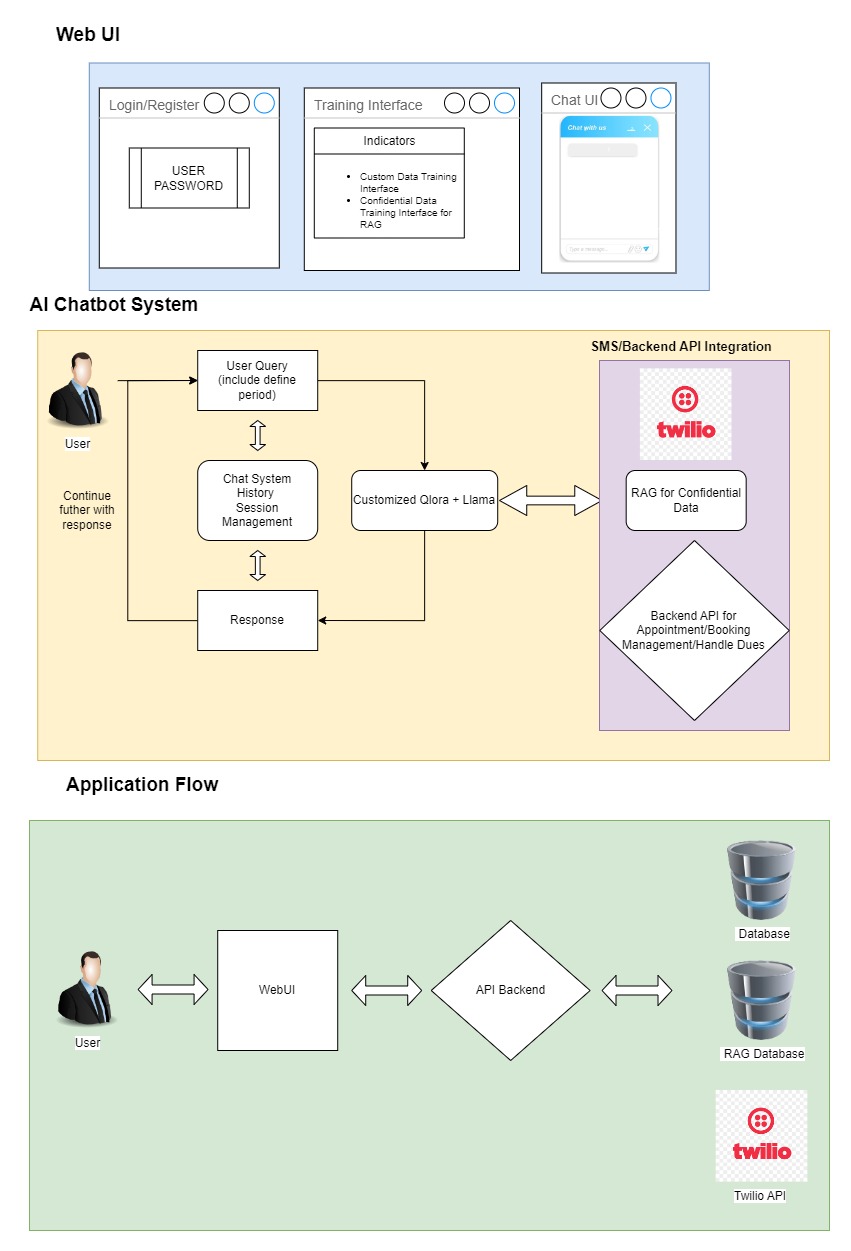
Solution Overview ➖
The solution architecture is designed to integrate various components to provide a seamless user experience. The architecture includes:
- Custom QLoRA Model Training: Training open-source models like LLaMA and Mixtral with domain-specific data to ensure accurate and relevant responses.
- Twilio SMS Integration: Utilizing Twilio’s API to send and receive SMS for appointment confirmations, reminders, and other notifications.
- RAG for Confidential Data: Implementing Retrieval-Augmented Generation (RAG) using ChromaDB for secure and efficient access to confidential data.
- API Development with FastAPI: Building RESTful APIs using FastAPI to handle communication between the frontend and backend, and to manage data transactions.
- Backend Functionality: Handling all other functionalities such as booking, appointments, dues management, and order tracking through robust backend API services.
QLoRA Model Training
QLora- QLoRA is the extended version of LoRA which works by quantizing the precision of the weight parameters in the pre-trained LLM to 4-bit precision. Typically, parameters of trained models are stored in a 32-bit format, but QLoRA compresses them to a 4-bit format. This reduces the memory footprint of the LLM, making it possible to finetune it on a single GPU. This method significantly reduces the memory footprint, making it possible to run LLM models on less powerful hardware, including consumer GPUs.
The QLoRA model training involves the following steps:
- Data Collection: Gather domain-specific data including FAQs, appointment details, and patient interactions.
- Preprocessing: Clean and preprocess the data to ensure it is suitable for model training.
- Training: Utilize QLora training platforms to train the LLaMA or Mistral models on GPU resources.
- Fine-Tuning: Fine-tune the model using QLora Models.
- Evaluation: Evaluate the model performance and make necessary adjustments.
Technology Stack➖
- Programming Language: Python, Javascript
- AI API: FastAPI
- Backend: Django
- LLM Models: LLaMA/ Mixtral
- Database: Postgres
- Vector Database: ChromaDB (for vector storage)
- API Framework: FastAPI
- SMS Integration: Twilio
- Hosting: AWS/ GCP/Azure
LLM Selection➖
LLM Selection: Mistral 7B / Llama 2 7B / Llama 3 8B
Selection Criteria
The selection of the LLM (Large Language Model) will be based on the performance evaluation of three open-source models: Mistral 7B, Llama 2 7B, and Llama 3 8B. The primary criteria for selection include:
- Performance: The accuracy and relevance of responses during testing phases.
- Resource Efficiency: Ability to run efficiently on CPUs and low VRAM GPUs.
- Scalability: Ease of scaling the model for increased usage without significant degradation in performance.
- Compatibility: Integration with existing infrastructure and ease of use in the deployment environment.
Testing and Evaluation
Each model will be subjected to a series of tests designed to measure their performance in real-world scenarios. These tests will include:
- Accuracy Tests: Evaluating the correctness and relevance of the responses provided by the models using a diverse set of queries.
- Resource Utilization Tests: Monitoring CPU and GPU usage to ensure models run efficiently on limited resources.
- Latency Tests: Measuring response times to ensure the chatbot can handle real-time interactions smoothly.
- Scalability Tests: Testing the models under increased load to ensure they can handle a growing number of users without performance issues.
Models Under Consideration and Reasoning Behind Their Selection
- Mistral 7B
- Overview: Mistral 7B is known for its efficiency and ability to provide accurate responses with lower computational requirements.
- Strengths: High accuracy and relevance in responses, efficient use of computational resources, and good scalability.
- Use Cases: Ideal for scenarios requiring fast and accurate responses with minimal resource usage.
- Llama 2 7B
- Overview: Llama 2 7B builds on the strengths of its predecessor with improvements in performance and efficiency.
- Strengths: Enhanced accuracy, better resource utilization, and improved response times.
- Use Cases: Suitable for deployments where slightly better performance is required without significantly increasing resource consumption.
- Llama 3 8B
- Overview: The latest in the Llama series, Llama 3 8B offers the highest performance among the three models under consideration.
- Strengths: Superior accuracy and relevance, efficient performance on low VRAM GPUs, and excellent scalability.
- Use Cases: Best for applications needing the highest accuracy and capable of handling more complex queries while still being resource-efficient.
Final Selection
The final selection will be made based on the comprehensive evaluation of the models during the testing phase. The model that demonstrates the best overall performance in terms of accuracy, efficiency, and scalability will be chosen for deployment. This approach ensures that the chosen model will not only meet the current requirements but will also be capable of scaling with future needs, providing a robust and reliable solution for the AI chatbot.
By focusing on models that are optimized for both CPUs and low VRAM GPUs, we ensure cost-effective deployment and operation, making the solution accessible and sustainable for a wide range of applications.
Milestone Documentation➖
Milestone 1: Initial Setup and Model Training
- Setup development environment
- Collect and preprocess data
- Train and fine-tune the QLoRA model
- Test various Open Source Models and evaluate their performance.
- Develop basic API endpoints using FastAPI
Milestone 2: Frontend/Backend Development and Integration
- Implement frontend and backend functionalities for booking, appointments, dues management, and order tracking
- Integrate ChromaDB for confidential data handling and RAG.
- Create API endpoints to support full functionality
- Conduct initial testing and validation
- Integrate Twilio for SMS functionality
Milestone 3: Payment Gateway Integration
- Integrate payment gateway.
- Implement payment processing for premium features.
Milestone 4: Deployment and Testing
- Deploy the solution on cloud infrastructure
- Conduct thorough testing to ensure reliability and performance
- Implement periodic test transitions and demos
- Optimize for production and prepare for launch
Milestone 5: Deployment and Testing
- Deploy the solution on cloud infrastructure
- Conduct thorough testing to ensure reliability and performance
- Implement periodic test transitions and demos
- Optimize for production and prepare for launch
Milestone 6: Documentation & Maintenance
- Perform the final round of testing and bug fixes.
- Prepare documentation and training materials.
- Provide post-launch support and maintenance.
